

Overview #
IRP offers failover capabilities that ensure Improvements are preserved in case of planned or unplanned downtime of IRP server.
IRP’s failover feature uses a master-slave configuration. A second instance of IRP needs to be deployed in order to enable failover features. For details about failover configuration and troubleshooting refer Failover Configuration.
IRP’s failover solution relies on:
- slave node running same version of IRP as the master node,
- MySQL Multi-Master replication of ‘irp’ database,
- announcement of the replicated improvements with different LocalPref and/or communities by both nodes,
- monitoring by slave node of BGP announcements originating from master node based on higher precedence of master’s announced prefixes,
- activating/deactivating of slave IRP components in case of failure or resumed work by master,
- syncing master configuration to slave node.
An overview of the solution is presented in the following figure:
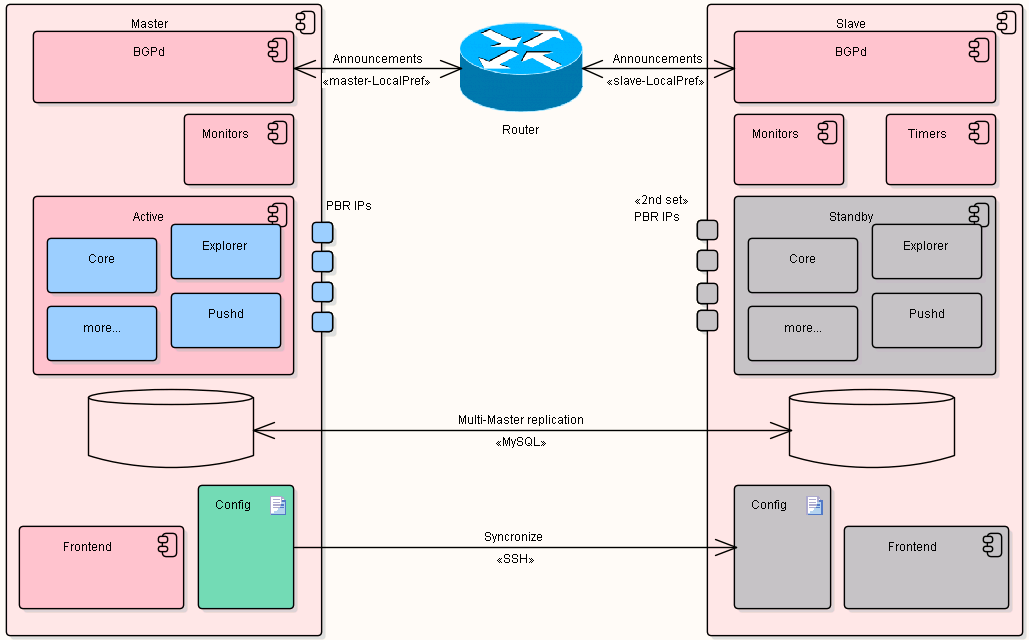
Figure 1.2.10: Failover high level overview
The diagram highlights the:
- two IRP nodes – Master and Slave,
- grayed-out components are in stand-by mode – services are stopped or operating in limited ways. For example, the Frontend detects that it runs on the slave node and prohibits any changes to configuration while still offering access to reports, graphs or dashboards.
- configuration changes are pushed by master to slave during synchronization. SSH is used to connect to the slave.
- MySQL Multi-Master replication is setup for ‘irp’ database between master and slave nodes. Existing MySQL Multi-Master replication functionality is used.
- master IRP node is fully functional and collects statistics, queues for probing, probes and eventually makes Improvements. All the intermediate and final results are stored in MySQL and due to replication will make it into slave’s database as well.
- Bgpd works on both master and slave IRP nodes. They make the same announcements with different LocalPref/communities.
- Bgpd on slave node monitors the number of master announcements from the router (master announcements have higher priority than slave’s)
- Timers are used to prevent flapping of failover-failback.
Requirements #
The following additional preconditions must be met in order to setup failover:
- second server to install the slave,
- MySQL Multi-Master replication for the irp database.
- a second set of BGP sessions will be established,
- a second set of PBR IP addresses are required to assign to the slave node in order to perform probing,
- a second set of improvements will be announced to the router,
- a failover license for the slave node,
- Key-based SSH authentication from master to slave is required. It is used to synchronize IRP configuration from master to slave,
- MySQL Multi-Master replication of ‘irp’ database,
- IRP setup in Intrusive mode on master node.
Failover #
IRP failover relies on the slave node running the same version of IRP to determine if there are issues with the master node and take over if such an incident occurs.
Slave’s Bgpd service verifies that announcements are present on a router from master. If announcements from master are withdrawn for some reason the slave node will take over.
During normal operation the slave is kept up to date by master so that it is ready to take over in case of an incident. The following operations are performed:
- master synchronizes its configuration to slave. This uses a SSH channel to sync configuration files from master to slave and process necessary services restart.
- MySQL Multi-Master replication is configured on relevant irp database tables so that the data is available immediately in case of emergency,
- components of IRP such as Core, Explorer, Irppushd are stopped or standing by on slave to prevent split-brain or duplicate probing and notifications,
- slave node runs Bgpd and makes exactly the same announcements with a lower BGP LocalPref and/or other communities thus replicating Improvements too.
In case of master failure its BGP session(s) goes down and its announcements are withdrawn.
The same announcements are already in router’s local RIB from slave and the router chooses them as best.
At the same time, Failover logic runs a set of timers after master routes are withdrawn (refer global.failover_timer_fail ). When the timers expire IRP activates its standby components and resumes optimization.
Failback #
IRP includes failback feature too. Failback happens when master comes back online. Once Bgpd on the slave detects announcements from master it starts its failback timer (refer global.failover_timer_failback). Slave node will continue running all IRP components for the duration of the failback period. Once the failback timer expires redundant slave components are switched to standby mode and the entire setup becomes normal again. This timer is intended to prevent cases when master is unstable after being restored and there is a significant risk it will fail again.
Recovery of failed node #
IRP failover configuration is capable to automatically restore its entire failover environment if downtime of failed node is less than 24 hours.
If downtime was longer than 24 hours MySQL Multi-Master replication is no longer able to synchronize the databases on the two IRP nodes and manual MySQL replication recovery is required.
Upgrades #
Failover configurations of IRP require careful upgrade procedures especially for major versions.