 When flying, it’s important to choose the right airline. Obviously, a direct connection is usually best, but if a layover is necessary, it helps if the intermediate stop is not too much out of the way, and the airport in question can handle the passenger load without delays or cancellations. The Internet works exactly the same way—except that most customers are frequent fliers with just one Internet Service Provider. However, customers who are prepared to run the Internet’s BGP routing protocol themselves are in the position to connect to two or more ISPs, and can then send packets for each destination through the ISP that provides the highest quality path to that destination. BGP has a set of rules to determine the best path to reach a destination, but those rules don’t take into account the most important properties that determine user experience: latency and packet loss. Latency is the time it takes for packets to find their way to the destination (and back), and packet loss is the percentage of packets that fail to make it to the destination, creating additional delays until a retransmitted copy arrives.
When flying, it’s important to choose the right airline. Obviously, a direct connection is usually best, but if a layover is necessary, it helps if the intermediate stop is not too much out of the way, and the airport in question can handle the passenger load without delays or cancellations. The Internet works exactly the same way—except that most customers are frequent fliers with just one Internet Service Provider. However, customers who are prepared to run the Internet’s BGP routing protocol themselves are in the position to connect to two or more ISPs, and can then send packets for each destination through the ISP that provides the highest quality path to that destination. BGP has a set of rules to determine the best path to reach a destination, but those rules don’t take into account the most important properties that determine user experience: latency and packet loss. Latency is the time it takes for packets to find their way to the destination (and back), and packet loss is the percentage of packets that fail to make it to the destination, creating additional delays until a retransmitted copy arrives.
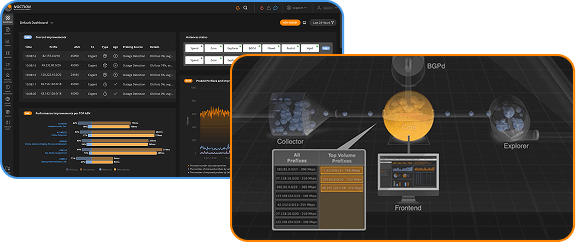
Route optimization products such as Noction’s Intelligent Routing Platform (IRP) go beyond BGP’s limited best path selection mechanism, and allow a network that is connected to multiple ISPs to use the best available path towards each destination. For this, the route optimization device sends probes over each path to compare latency and loss between them. It then selects the best path from the ones present within BGP. Latency and packet loss vary over time, due to normal daily usage cycles and changes in connectivity and traffic flow throughout the Internet. With this in mind, good route optimization devices probe paths at regular intervals.
An important consideration when sending probes is the overhead this generates for remote networks, which are the targets of the probes. Noction IRP employs a number of measures to limit the amount of probes while still adapting to changing network conditions quickly. Another important consideration is the benefit re-routing a flow might bring. So probing has to be efficient as well as effective.
An efficient probing process is one that uses the least amount of resources to produce the required network performance data.
An effective probing process is one that identifies the most important opportunities that we can act upon. Below we’ll discuss the way Noction IRP uses probes to determine the best path towards remote Internet subnetworks.
Improving for value
Everybody has the intuition that not all networks are made equal —compare huge destinations such as Facebook or Google with a local community website on the other side of the world. The more valuable and less valuable networks differ by a huge margin. Of course, even in the case of least valuable networks if we are using an optimal path or route, this will add some benefit to us, our customers and partners, and our reputation. Still, the effects of an improvement made to the most valuable as compared to the least valuable destination, are different. The numbers speak for themselves: a sample of a few customers shows that the traffic volume (in bytes) towards largest vs smallest is approximately 150 000 to 1. And that least valuable network is in fact one that registered on our radars—there are others that don’t. There are remote regional networks that never communicated with our network during the month we gathered our dataset. Find bellow ratios between the prefix that attracted the most traffic and subsequent prefixes in traffic volume where the graph plots values for powers of two up to N = 215.
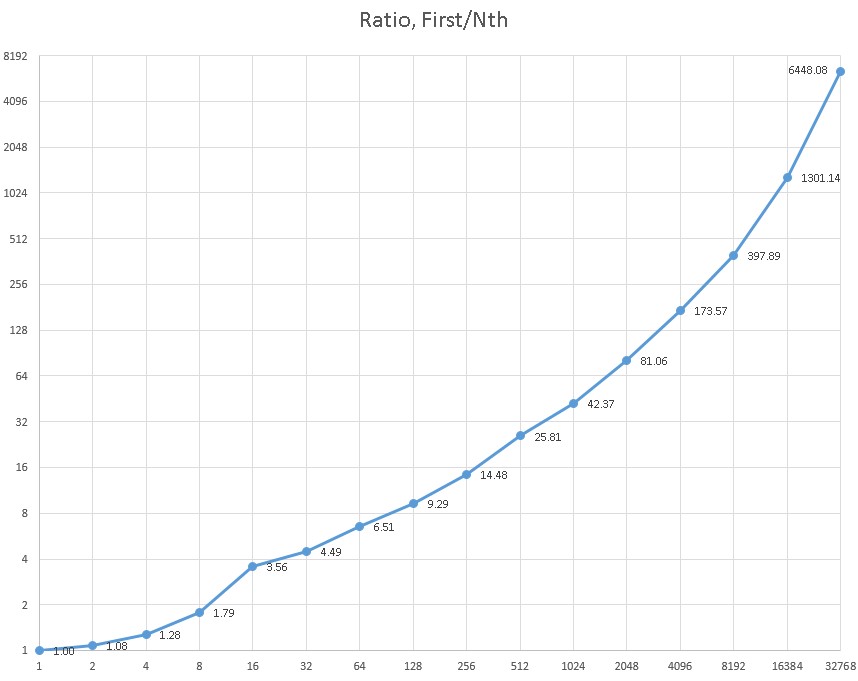
Given the above ratios it is helpful to split large networks into smaller subnetworks. This offers a few benefits:
– while large networks may cover a large geographic area, smaller subnetworks are more likely to be concentrated in a single location with homogenous network characteristics.
– the large network will be probed more frequently since even individual prefixes carry large volumes of traffic.
It is noteworthy that a subset of 50 000 subnetwork prefixes used in the data carry 99.9% of total traffic for our customer and represent only approximately 2.5% of the total 2-3 million subnetworks monitored by the customer’s IRP. There are approximately 550000 network prefixes in global BGP routing tables; IRP disaggregates larger networks into more granular prefixes in order to offer more granular control over parts of large networks as discussed above.
We focus on the most valuable prefixes because those attract almost all traffic.
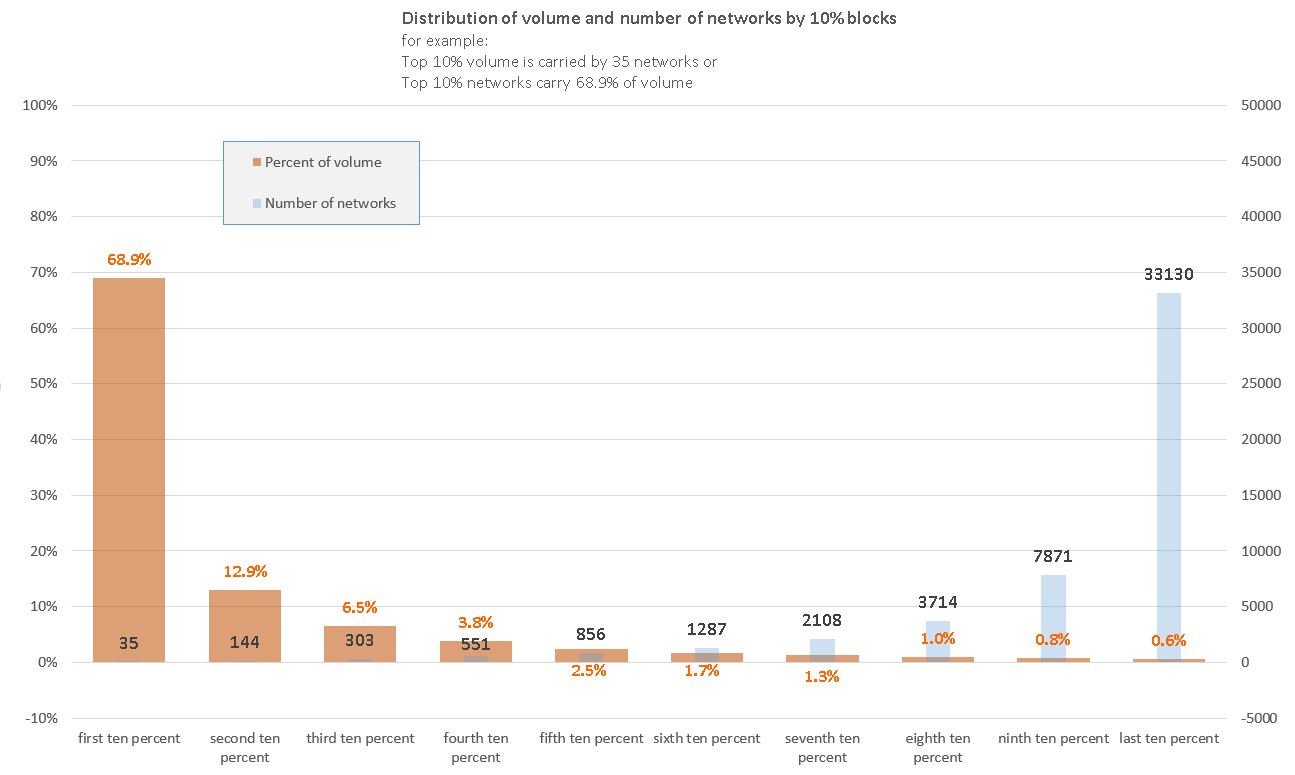
In the face of different constraints we should strive to first ensure that the most valuable prefixes are optimal before proceeding with analysis of less valuable ones and only when every other possible prefix is known to be optimal should we proceed with an evaluation of the least valuable prefixes.
Being a good citizen
Route optimizers probe continuously whatever networks are active at the moment and pushing relevant volumes of traffic. This ensures that optimizers operate on the most valuable opportunities to improve and with accurate current data. At the same time it should be taken into consideration that the remote networks that have never been improved before, will be examined more often.
Noction IRP uses three different types of probes: UDP, ICMP and TCP SYN packets. By using a separate IP address for ISP and policy routing, it is possible to probe non-active paths as well as the currently active path towards each destination prefix.
This might cause some of the networks to receive a continuous stream of probe packets, which may flag alerts for network administrators or trigger a security or rate control mechanism in those networks. This is definitely not desirable. It is preferable that the optimizer limits the number of probes it sends and thus behaves like a good Internet citizen. Without having a sensible limit on the number of probes sent, probing packets will likely start to be dropped, which will lead to inaccurate probing results. Put simply, if you probe too often, you will actually achieve the opposite of what you are trying to achieve; bad routing changes instead of good ones.
Noction IRP employs several mechanisms to be a better netizen:
– Stop probing quickly if the destination is stable. IRP uses an intelligent strategy by sending only a small batch of 5 control packets (the number is configurable) to establish performance characteristics through different providers. These are referred further as Fast Probes. If all the packets get a consistent response, the Fast Probe succeeds and its performance metrics are considered reliable.
– Send a Full Probe (100 packets, configurable) only if the Fast Probe failed to achieve consistent results.
– Don’t allow probing of a destination network if it was probed recently.
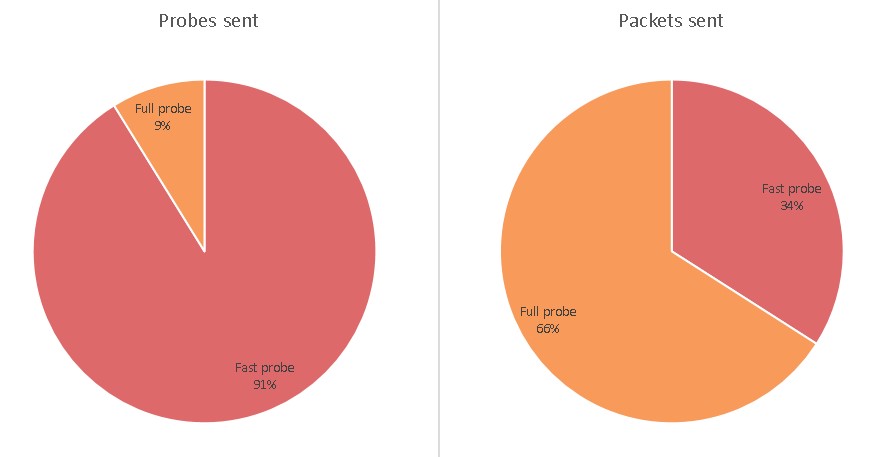
The pie charts below highlight that more than 90% of probes are in fact Fast Probes, which spare the destination network the burden of processing an excessive number of control packets. At the same time, less than 10% Full Probes generate more than two thirds of total control packets for situations that require more careful attention.
While reliance on Fast Probes mitigates part of the control packet issue, it still presents a possibility for bad behavior on the IRP’s part due to the fact that probes, even Full Probes, only provide information about a single point in time, while network conditions may change rapidly. Thus, while three- or four thousand control packets in three hours does not seem excessive because the probe ran for a few seconds or a couple of minutes at most, all those packets come in significantly larger numbers.
The scatterplot below highlights the number of packets received by a prefix (vertical axis) during each of the 180 minutes (horizontal axis) of the analyzed interval. Green dots represent about 200 packets or less. Yellow is centered at about 500 packets and red represents roughly 1000 packets or more. No dot means no packets were sent during that particular minute.
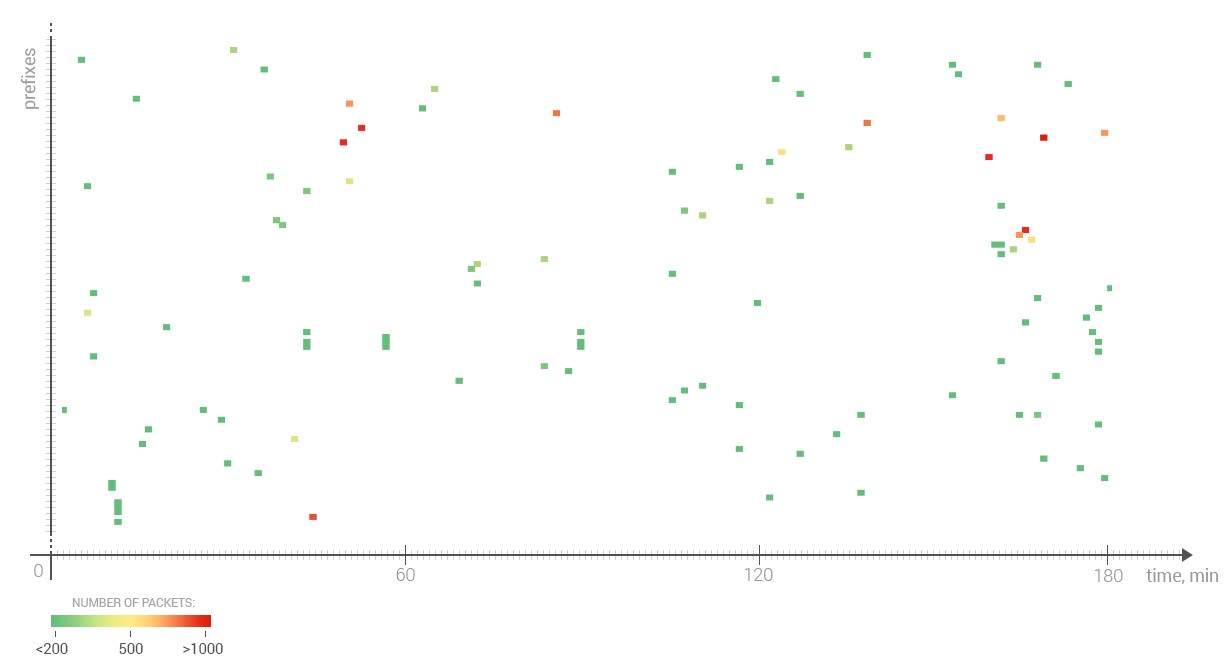
While most dots are green, there is a small number of red dots indicating 1000 probe packets or more during a particular minute. This happens even after precautions were taken in IRP to protect against excessive numbers of packets reaching a destination network and potentially triggering Denial-of-Service alerts.
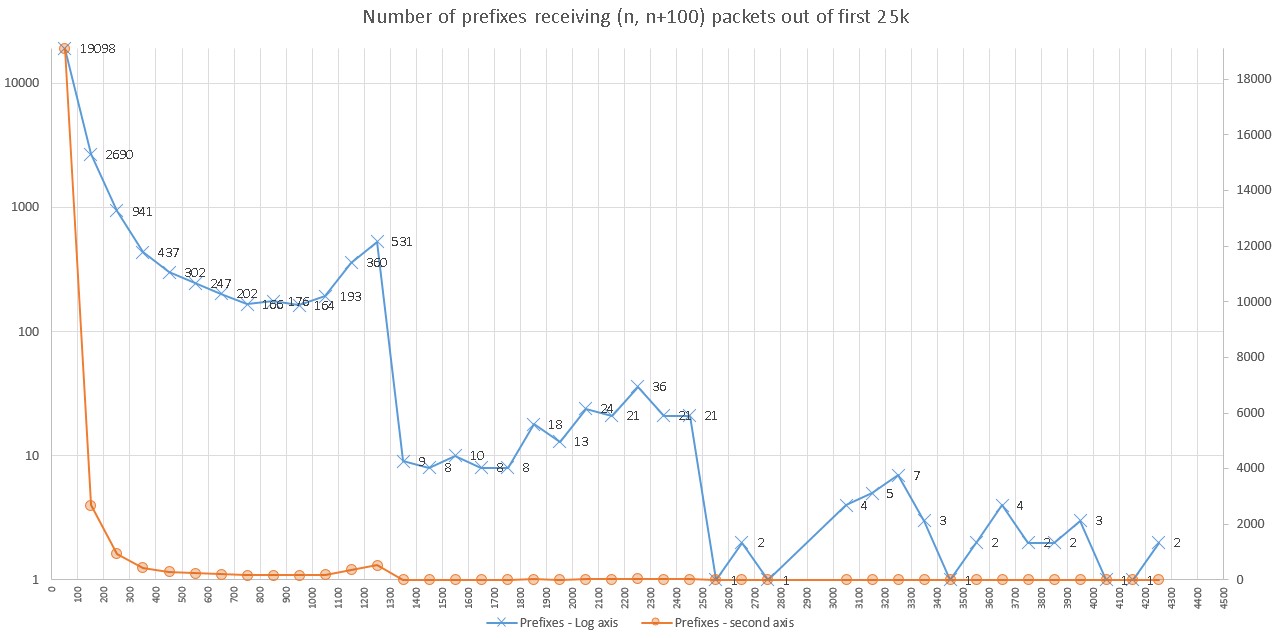
Sending several thousand probe packets within a three-hour period doesn’t seem excessive, but this level of probing is still undesirable, as the destination networks may be unhappy about receiving the probe packets and it’s important to protect the reputation of the IRP as a good netizen.
Route stability
Routing table stability is a good thing and represents another driving factor towards probing conservatively. Each path change requires processing the update in routers and communicating the changes between them. This is undesirable as many routers’ resource utilization is quite high.
Also, small fluctuations in network performance or imprecise measurements might trigger a cascade of back-and-forth changes that stress edge routers, but don’t result in real-world latency or packet loss improvements. To avoid this, paths should only be changed when probing indicates this is clearly beneficial.
To accomplish this, a tentative route change may be deferred for a short time and the destination network reprobed to confirm initial findings. If the change is confirmed, the path is changed, but if not, the previous route will be maintained since there is no clear benefit to making the change.
In order to maintain stability, once path changes are made, the path for that particular network is kept the same for a configurable amount of time. During that time, the amount of traffic to that network may drop below the thresholds for probing. This might cause the prefix not to be queued for regular probing for a significant amount of time. All the while, performance may suffer even though the problems on the original path have been resolved and switching back to the original path would improve performance. To avoid this, prefixes that have been rerouted will be re-probed to confirm the path change is still beneficial at least once every one to three hours (configurable).
Data use
As stated above, it is necessary to limit probing, especially excessive probing of particular destinations.
At the same time it is clear that:
– More probes that cover a larger fraction of the Internet give IRP the opportunity to identify more problems, and
– More frequent probes provide more up-to-date performance metrics and allow for better decisions
So it’s necessary to carefully balance between the two needs. While all the above drivers have configurable parameters that increase or decrease the relevancy of prefixes and the frequency they are probed, there are two additional sets of IRP features that allow network administrators to fine-tune probing.
First, it’s possible to designate “VIP prefixes” that indicate parts of the Internet that are of particular interest to our customer. VIP prefixes will be probed even during non-peak hours and possibly in advance of peak hours. They are also probed with customer-configurable frequency. Static policies prevent probing of some destinations while allow/deny policies reduce the number of control probing packets by only choosing a subset of available providers to probe through.
Second, the customer can configure Commit Control or Cost Optimization, which then use information gained from recently sent probes to optimize the bandwidth use of Internet connections make the best use of bandwidth commitments and minimize usage charges.
Performance improvements are made immediately once probing has finished. Later on, if IRP detects some cost saving opportunities probes from the recent past are be used to determine if it makes sense to reroute some unimproved prefixes to realize these cost savings, by reducing bandwidth usage on overloaded providers or by choosing a lower priced route. Of course, neither Commit Control nor Cost Optimization allow performance degradation above measurement error.
TCP analysis can also provide plenty of useful data that could be used to prioritize probing. Administrators can configure port mirroring between IRP and the edge router to provide a copy of the traffic flow for analysis. One of the important performance indicators is the Packet Retransmission. An excessive number of packet retransmission could indicate link errors or too much buffering in network routers and switches. Therefore the destinations that are affected by an excessive number of packet retransmits should receive a high priority in probing.
Another algorithm that directs probing towards affected destinations is the Outage Detection mechanism. A complete traffic path from source to destination typically passes through multiple networks, with different AS numbers. This is reflected in the traceroute results. If Outage Detection is enabled in the IRP configuration, the system gathers network performance information for all traceroute hops over which the traffic passes to the remote networks. Next, each hop is translated into AS numbers. In case any network anomalies are detected on a specific ASN, then this ASN and the immediate neighbor ASN are declared a problematic AS-pattern. The system then re-probes the prefixes that pass through this AS-pattern. In case the issue is confirmed, all related prefixes are rerouted to the best performing alternate provider. The Outage Detection mechanism uses a statistical algorithm for selecting the best routing path. Rerouting will occur for all the prefixes that are routed through the affected as-pattern, despite their current route.
We hope that this article has shed some light on how the Noction IRP balances the need to optimize traffic flow with the imperative to be a good netizen as well as optimize cost where possible.