As explained in our last blog post, packet loss and latency can seriously impact application performance. There’s not much we can do about latency, because most of it is a result of distance. If that’s not the problem, it’s the buffering of packets in routers, which can be solved by buying more bandwidth. Packet loss, however, can be harder to fix. But if your network experiences notable packet loss, you should absolutely consider getting rid of it. This will make applications perform better and thus make your users happier. Better application performance can easily translate in more sales in an ecommerce or service provider environment. And making your users happier is just good karma.
As explained in our last blog post, packet loss and latency can seriously impact application performance. There’s not much we can do about latency, because most of it is a result of distance. If that’s not the problem, it’s the buffering of packets in routers, which can be solved by buying more bandwidth. Packet loss, however, can be harder to fix. But if your network experiences notable packet loss, you should absolutely consider getting rid of it. This will make applications perform better and thus make your users happier. Better application performance can easily translate in more sales in an ecommerce or service provider environment. And making your users happier is just good karma.There are two main reasons packets get lost: transmission errors and congestion. There’s a lot of moving parts that get packets from A to B. Random noise will flip a bit once in a while, usually causing a CRC error. Maybe a cable is too long, or the cable or hardware is slightly out of spec, causing clock skew errors and more. Usually, routers and switches can report such errors on their interfaces/ports. If there’s many of these errors, you’ll have to investigate the hardware and the cabling. Unfortunately, both can be expensive to replace, and replacements may suffer from the same errors.
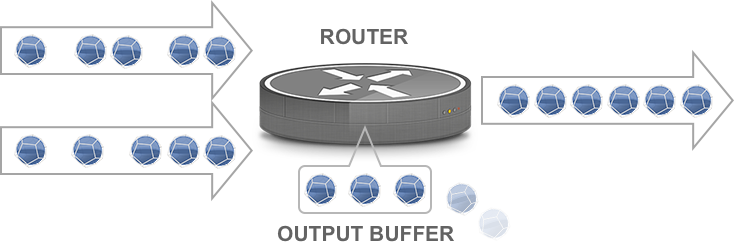
Then there’s congestion. Obviously, if you’re trying to transmit 1001 megabits per second over a 1 Gbps link, something has to give. However, you can still have short-lived congestion even on links that don’t seem to be overloaded at all. Network traffic can be incredibly bursty, and if a burst of packets needs flows from a fast interface towards a slower one, or if two or more bursts come together, then it’s possible that the buffer space for the outgoing interface fills up and packets have to be dropped. These are “output drops” in interface statistics.
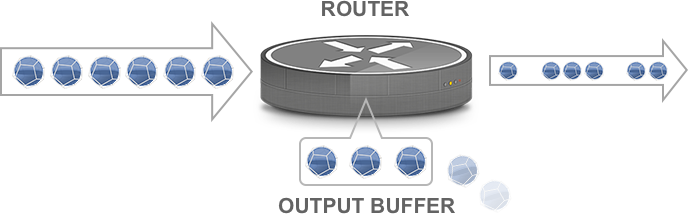
Packets arrive faster than they can be transmitted; some are dropped
(A different beast are input drops. Packets that the router’s CPU should handle go into an input queue. Once that queue is full, additional packets are dropped. Regular packets on their way to a remote destination don’t cause input drops on most routers; input drops are usually caused by a busy CPU or an excess of ARP or similar traffic.)
Packet loss due to short-lived congestion can be addressed by increasing the queue length for the router or switch interface in question. If a 10-packet queue would drop the last two packets of a 12-packet burst, a 20-packet queue will accommodate that burst without loss. Unfortunately, long-lived TCP transfers tend to fill up buffer space in routers and switches that are a bandwidth bottleneck. So if a download has an average of 15 packets in the 20-packet queue, that same 12-packet burst may see half of its packets get lost.
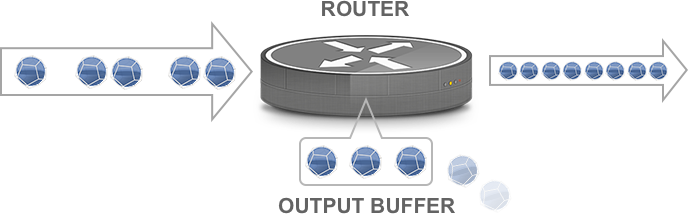
Input and output bandwidth are equal: the router is not a bottleneck
A more effective solution is to remove the bandwidth bottleneck, so packets can be transmitted as fast as they’re received. So if a router as a 1 Gbps link coming in and a 100 Mbps link going out, upgrade the latter to 1 Gbps, and short-lived congestion will clear up. But when a router (or switch) has more than two ports, matching input and output speeds quickly becomes impractical. Still, there are situations where it’s helpful to increase or decrease port speeds to reduce the differences in bandwidth between hops in a network path.
Multiple inputs, one output: the router is again a bottleneck
In addition to looking at interface statistics, you can also debug packet loss problems with the ping command. On many Unix(like) systems, you can use the -l flag to “preload” a number of ping packets. For instance, on MacOS or BSD, you can use this command to stress test your network:
ping -s 1400 -c 100 -l 250 192.0.2.1
You have to be root to execute this command. By specifying -s 1400 we use large packets (1428 bytes) so the buffer doesn’t get a chance to drain very quickly. -c 100 means we send 100 packets, and -l 250 makes sure the first 250 packets (i.e., all 100 in this case) are sent as quickly as possible. If you then consistently get (for instance) a little under 30 replies back, the buffer at the bottleneck hop is probably 30 packets in size. This is a good way to identify network hops with small buffers. And a ping without -l but maybe -c 300 runs for five minutes (one packet per second 300 times) and will give you a good idea about your average packet loss, or use a tool like SmokePing to continuously monitor your network.
After we’ve done these measurements, let’s look at queue/buffer sizes a bit more. Very small buffers will cause many “tail drops” (packets are dropped because buffers are full) if the device is a bandwidth bottleneck. On the other hand, larger buffers can cause bufferbloat-induced latency, and if buffers fill up, tail drops can still happen.
So what’s the solution?
First and foremost, it’s important to remove persistent bandwidth bottlenecks. It may also be necessary to replace lower-end routers or switches that simply don’t have enough buffer space to accommodate for the type of burstiness that your network experiences. In addition to that, it’s important to use appropriate active queue management (AQM).
AQM algorithms try to drop packets before buffer space runs out in a way that will make TCP slow down appropriately rather than dropping many packet at once when the buffer is full, which slows down TCP much more than necessary. To add insult to injury, TCP sessions will experience drops at the same time, and start “synchronizing”, leading to a pathological cycle of ramp up, drops, slow down.
Back in 1998, the IETF recommended the use of random early detect (RED, also sometimes random early drop or random early discard). What RED does is use a fairly large buffer, and then keep track of how full the buffer has been recently. If the buffer has been fairly empty, no packets are dropped. However, if the buffer was pretty full recently, some packets are dropped even if there is enough buffer space now. RED works fairly well, but it has the downside that it requires tuning of its parameters to work well. If the parameters are set incorrectly, it is possible (although not especially likely) that performance is worse than in the default tail drop situation.
Note that QoS (quality of service) mechanisms don’t remove the need for AQM: QoS makes sure certain applications get preferential treatment, while AQM optimizes latency and packet loss, so applications can make full use of the network bandwidth. There are many more advanced AQM algorithms than RED, which require less or no manual tuning. However, availability varies from vendor to vendor.
Finally, the most proactive approach you can take to bypass congestion is to use automated solutions such us Noction Intelligent Routing Platform that can fully automate the route optimization process based on packet loss and latency measurements it takes by actively probing Internet destinations.