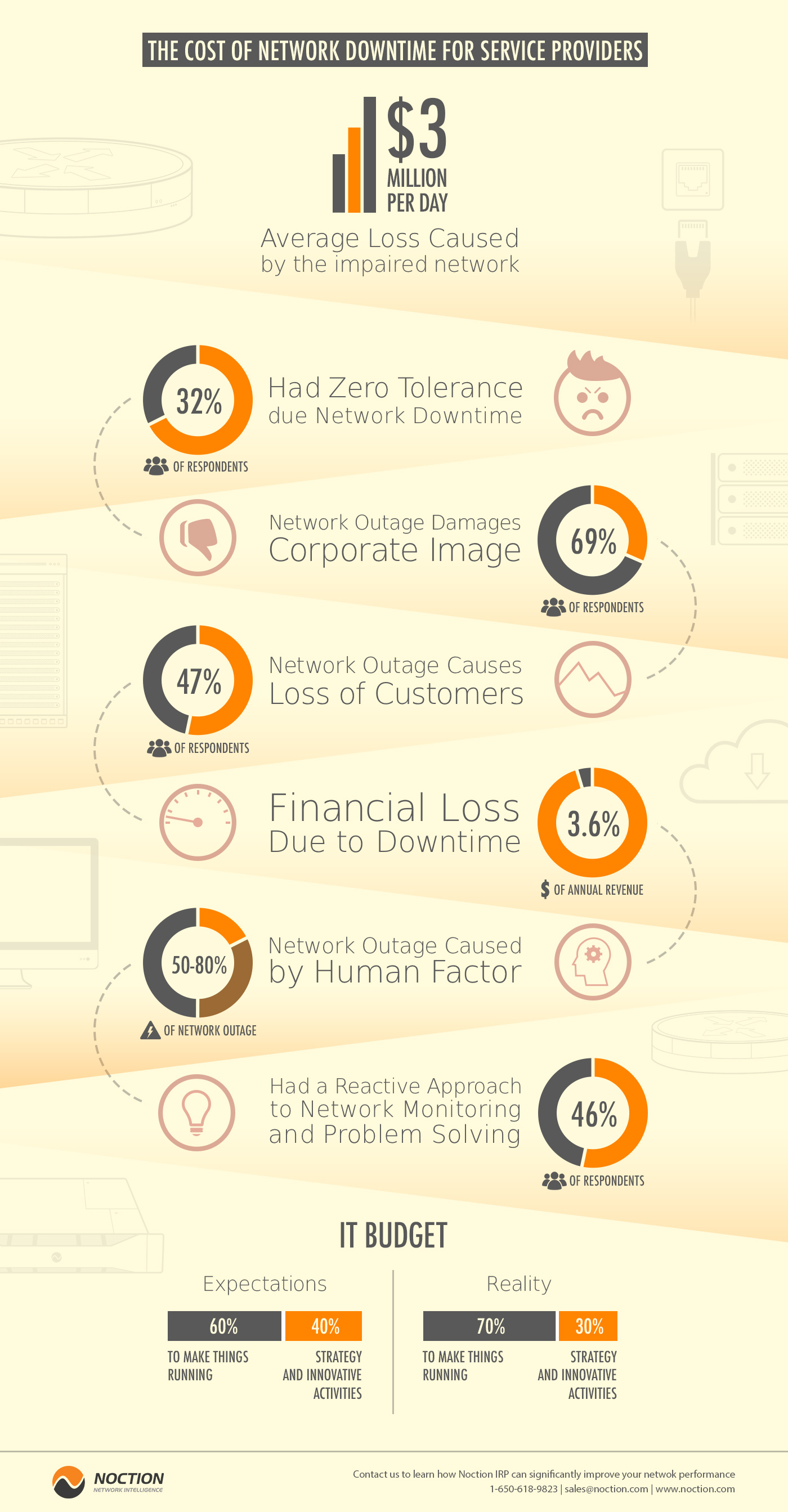
An operational network is a strategic business resource. It carries everyday messages and mission-critical data, and facilitates communication between people and business processes. It is, probably, invisible to many people in the company, who, perceive it as a utility, like water or electricity. And just like with those utilities, its essentialness becomes apparent when it’s not there. According to an earlier study by Infonetics Research an average of 3.6 percent of annual revenue in large businesses is lost due to downtime.
An operational network is a strategic business resource. It carries everyday messages and mission-critical data, and facilitates communication between people and business processes. It is, probably, invisible to many people in the company, who, perceive it as a utility, like water or electricity. And just like with those utilities, its essentialness becomes apparent when it’s not there. According to an earlier study by Infonetics Research an average of 3.6 percent of annual revenue in large businesses is lost due to downtime.
What happens when the network is not available? A network outage can have a significant impact on a corporation’s image and its customers. Employees can’t get access to email, phones or critical business applications. Correspondingly, business processes aren’t updated and customers may start to look elsewhere for the information they seek, or for the product or service they need to order.
A recent study of technology decision makers shows how important it is to investigate the factors that cause network downtime. The Strategy Group conducted a survey that included 173 respondents from Ziff Davis Enterprise database. These were all manager level or higher, working in organizations with more than 100 employees. This group demonstrated the increasing lack of tolerance for network downtime. Almost 1/3 (32 percent) said that they had zero tolerance, and the average response of the group was just 1.8 hours. It is quite understandable, given that the estimated average loss, caused by the impaired network, is around $3 million per day, with 10 percent of respondents giving an estimate of more than $10 million in damages and lost revenue per day.
The negative consequences of a network outage are not just financial. Damage of the corporate image was the biggest concern of the respondents (69 percent), with loss of customers close behind (47 percent). Given these potential consequences, it is not surprising that 70 percent of the average IT budget is oriented towards keeping things running and only 30 percent towards strategic and innovative activities. Overall, the group wanted to see this change over the next 12-18 months, moving towards a 60/40 split.
Almost half of the group (46 percent) had a reactive approach to network monitoring and problem solving. It is interesting to note that companies with a proactive or strategic approach spend a smaller percentage of their budget just keeping things running (60 to 65 percent), compared to those with a reactive or chaotic approach (75 to 80 percent). The lower rate may indicate a virtuous cycle of benefit, as the companies working proactively continue to innovate and improve their IT operations and outperform their reactive competitors.
Operations teams face many challenges, when they try to increase the network availability. Outages attributable to network equipment generally fall into one of the three categories: planned maintenance events, system errors, or human factors. Networking vendors typically focus on the first two, but the last one, human factors, is the biggest contributor—responsible for 50 to 80 percent of network outages.
Looking for someone to blame is a natural response to outages caused by human error, but, unfortunately, it doesn’t help to improve network availability. In complex systems like modern computer networks, human error is more a symptom of complexity than a root cause.
The performance of IP networks depends on a wide variety of dynamic conditions. Traffic shifts, equipment failures, planned maintenance, and topology changes in other parts of the Internet, can all decrease the performance. To maintain good performance, network operators must continually reconfigure their routing processes. Operators deploy BGP to control the traffic flow to neighboring Autonomous Systems (ASes), as well as how traffic traverses their networks. However, because BGP route selection is indirectly controlled by configurable policies, and influenced by complex interactions with intra-domain routing protocols, operators cannot predict how a particular BGP configuration would behave in practice.
When the performance problems arise or network conditions change, network operators are forced to adjust routers configuration to provide low latency, high throughput, and high reliability. For example, an operator might adjust the configuration to respond to network congestion or equipment failures, or to prepare for planned maintenance. However, the complexity of the protocols, the large number of tunable parameters, and the size of the network make it extremely difficult for the operators to reflect on the effects of their actions. These limitations lead to human errors in configuring BGP. Therefore, the common approach of “tweak and pray” is no longer acceptable in an environment, where users have high expectations for performance and reliability. Consequently, unique solutions, based on more intelligent routing, should be deployed. Routing optimization systems such as Noction IRP allow automation of BGP routing decision-making. The IRP platform uses innovations in Intelligent Routing to minimize the occurrence of human errors and increase the overall network performance.