Once a BGP session is established, routers will exchange two types of messages: KEEPALIVE and UPDATE. Keepalive messages are sent to let a neighboring router know we are still alive, but just didn’t have any updates to send. The update message carries three types of information: a list of withdrawn routes, a set of path attributes and “network layer reachability information” (NLRI). If previously advertised prefixes are no longer reachable, they’re sent as withdrawn routes in an update. The NLRI field is simply a list of prefixes that are advertised as being reachable, and the path attributes field holds information about those advertised prefixes. There are four types of path attributes:
Once a BGP session is established, routers will exchange two types of messages: KEEPALIVE and UPDATE. Keepalive messages are sent to let a neighboring router know we are still alive, but just didn’t have any updates to send. The update message carries three types of information: a list of withdrawn routes, a set of path attributes and “network layer reachability information” (NLRI). If previously advertised prefixes are no longer reachable, they’re sent as withdrawn routes in an update. The NLRI field is simply a list of prefixes that are advertised as being reachable, and the path attributes field holds information about those advertised prefixes. There are four types of path attributes:- Well-known mandatory: all BGP routers must understand these and they must be present for all prefixes
- Well-known discretionary: all BGP routers must understand these, but they don’t have to be present
- Optional transitive: BGP routers are not required to understand these, but they must be passed along in updates to neighbors
- Optional non-transitive: BGP routers are not required to understand these, and if they don’t, the attribute must not be passed along in updates to neighbors
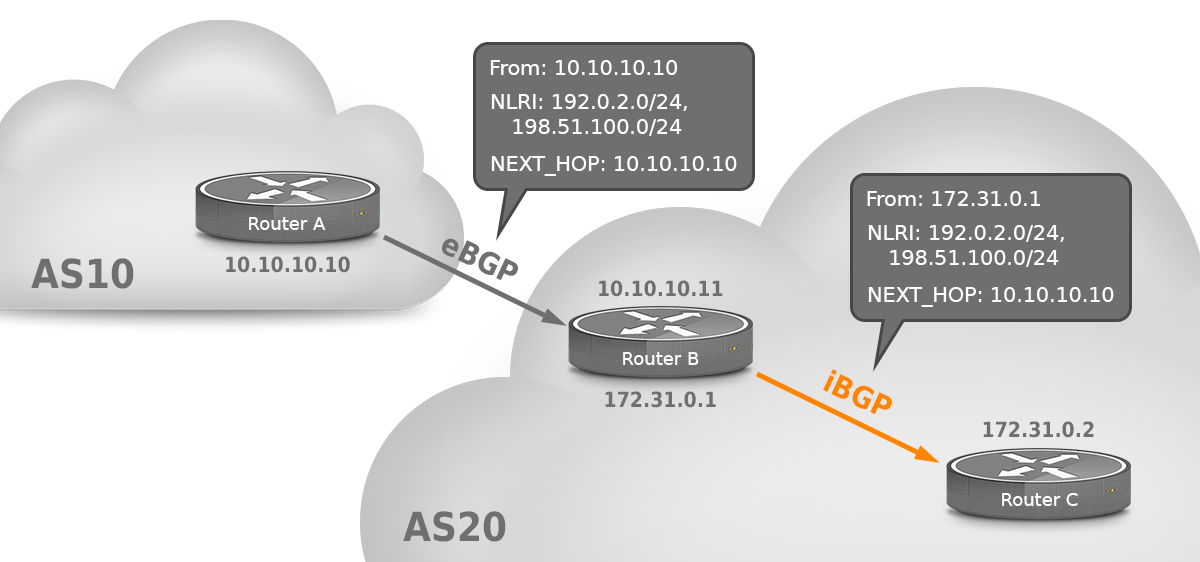
Today, we’ll be looking at the BGP NEXT_HOP attribute, which is a well-known mandatory attribute. When looking at a single router that has a BGP session towards another router in a different autonomous system — i.e., an external BGP or eBGP session—the next hop attribute is usually very boring: it simply contains the IP address of the neighboring router. IP packets towards an address covered in a prefix learned over BGP are forwarded to the IP address in the next hop attribute. When a router sends an update over eBGP, it updates the next hop attribute, normally with its own address on the interface that the update is transmitted over.
iBGP
However, there is a bit more to the next hop attribute. With internal BGP (iBGP) between routers within the same autonomous system, the NEXT_HOP is not updated. So in the figure, router B in AS 20 gets two prefixes from router A in AS 10 with 10.10.10.10 as the next hop. Router B simply sends packets to destinations such as 198.51.100.1 to 10.10.10.10, which is an address on a directly connected interface for router B. Router C, on the other hand, is not connected to the 10.10.10.x subnet, so it has no idea where those packets need to go.
The usual solution to this problem is to run an interior gateway protocol (IGP) such as OSPF and redistribute connected subnets into that IGP. Router C now knows that packets towards 198.51.100.1 go towards address 10.10.10.10 through BGP and that packets towards 10.10.10.10 go to router B through OSPF. So by doing a recursive routing table lookup router C knows to send packets with destination 1928.51.100.1 to router B. This also works if there are additional hops between routers B and C.
An alternative solution is to configure eBGP routers with next-hop-self. In that case, those routers will put their own address in the next hop attribute and there is no need for iBGP routers to know the subnets used for eBGP. This way, it’s possible to not have an IGP, as long as all the routers are directly connected to each other.
Denial-of-service mitigation
By using a route map, it’s possible to manually rewrite the next hop attribute. This is often useful in the face of (distributed) denial-of-service (DoS and DDoS) attacks. For instance, on a Cisco router, this configuration will update the next hop address to an address that is routed to the Null0 interface:
ip community-list 13 permit 65000:13
!
route-map customer-in permit 10
match community 13 set ip next-hop 13.13.13.13
!
ip route 13.13.13.13 255.255.255.255 Null0
!
The result is that if the 65000:13 community attribute is present on a prefix, all traffic towards that prefix is routed to the Null0 interface and dropped. An ISP can use this configuration to allow customers to have traffic for certain (sub-) prefixes or individual addresses filtered out so other prefixes (which don’t get the 65000:13 community) remain unaffected by the attack. Alternatively, traffic can be redirected to the address of a filter box that can look deeper inside the packets and remove the unwanted traffic.
Please note that it’s also possible to use a route map to update the next hop address when forwarding IP packets. This is a way to bypass normal routing table lookups and is known as “policy routing”, and should not be confused with modifying the next hop attribute in BGP or other routing protocols.
Route servers
On an internet exchange, a lot of routers from different autonomous systems are connected to a big, shared network. Organizations connected to the exchange can then set up BGP sessions between them as desired. However, on big exchanges with many members, this can be a lot of work. So most Internet Exchanges run one or two route servers. If you then connect to (peer with) the route server, you’re automatically connected to everyone else who is also connected to the route server. However, if the route server would include its own address in the next hop attribute for BGP updates it sends out, that would mean all the traffic between route server users would go through the route server. Fortunately, BGP is smarter than this. For instance, suppose 192.0.2.1 is the route server, with 192.0.2.2 and 192.0.2.3 being route server users. When the route server gets an update from 192.0.2.2, it knows that router 192.0.2.3 can reach 192.0.2.2 directly, because all three routers are connected to the same shared network. So the route server doesn’t update the next hop address in this case, and even though BGP updates flow through the route server, the actual traffic is exchanged directly between the routers of the internet exchange members.
IPv6
In our blog post on IPv4 BGP vs IPv6 BGP we talked about how it’s best practice to use separate eBGP sessions for IPv4 and IPv6. The reason for this is that the router can’t simply put the IP address for the local end of the BGP session in the next hop if the session runs over IPv4 and the prefixes are IPv6, or the other way around. Because the next hop isn’t updated for iBGP, sending both IPv4 and IPv6 prefixes over a single (IPv4 or IPv6) iBGP session is not an issue.
What we didn’t mention is that for IPv6, BGP actually exchanges two next hop addresses. Other routing protocols work over link local addresses—the addresses starting with fe80::/64 that IPv6 automatically configures on all interfaces. Link local addresses are necessary to generate proper ICMPv6 redirect messages, hence the need for BGP to know about them. However, using next hop addresses exclusively wouldn’t work in BGP because, as we saw earlier, iBGP routinely exchanges next hop addresses that are multiple hops away and are decidedly not “link local”. So, IPv6 BGP simply exchanges both. When using BGP commands such as show bgp ipv6 unicast <prefix> the regular global next hop address will show up, but with commands like show ipv6 route <prefix> a link local address may appear.