Like other very successful protocols such as HTTP and DNS, over the years BGP has been given more and more additional jobs to do. In this blog post, we’ll look at the new functionality and new use cases that have been added to BGP over the years. These include various uses of BGP in enterprise networks and data centers.
Like other very successful protocols such as HTTP and DNS, over the years BGP has been given more and more additional jobs to do. In this blog post, we’ll look at the new functionality and new use cases that have been added to BGP over the years. These include various uses of BGP in enterprise networks and data centers.
BGP for Internet routing
The world looked very different back in 1989 when the specification for the first version of BGP was published. Before BGP, there was the Exterior Gateway Protocol (EGP), but EGP was designed to have a central backbone that other networks connect to (similar to how OSPF’s area 0 connects other areas). As regional networks started to connect directly to each other and the first commercial network providers popped up, a more flexible routing protocol was needed to handle the routing of packets between the different networks that collectively make up the internet. Global “inter-domain” routing is of course still the most notable use of BGP.
In those early days of BGP, the Internet Protocol (IP) was just one protocol among many: big vendors usually had their own network protocols, such as IBM’s SNA, Novell’s IPX, Apple’s AppleTalk, Digital’s DECnet and Microsoft’s NetBIOS. As the 1990s progressed, these protocols quickly became less relevant as IP was needed to talk to the internet anyway, so it was easier to run internal applications over IP, too.
BGP in enterprise networks
The result was that BGP quickly found a role as an internal routing protocol in large enterprise networks. The reason for that is that unlike internal routing protocols such as OSPF and IS-IS, BGP allows for the application of policy, so the routing between parts of an enterprise can be controlled as necessary. Of course for inter-domain (internet) routing BGP is used with public IP addresses and public Autonomous System (AS) numbers. These are given out by the five Regional Internet Registries (RIRs) such as ARIN in North America. In enterprise networks, the private address ranges 10.0.0.0/8, 172.16.0.0/12 and 192.168.0.0/16 are often used, but, perhaps surprisingly, enterprise networks also tend to use public addresses, as coordinating the use of the private ranges becomes very complex very quickly in large organizations, especially after mergers.

Enterprise networks do tend to use private AS numbers extensively, as the RIRs have become more restrictive in giving out public AS numbers over time—despite the fact that as of about ten years ago we’ve moved from 16-bit to 32-bit AS numbers, so there is absolutely no shortage. The original 16-bit private AS number range is 64512 to 65534, allowing for 1023 private AS numbers. That’s not a lot in a large network, so it’s not uncommon for the same AS number to be used in different parts of the network. The 32-bit private range is 4200000000 to 4294967294, allowing for almost 95 million additional private AS numbers. So clashing AS numbers should no longer be a problem, as long as people more or less randomly select them, rather than all start at 4200000001.
Aside from these considerations, the structure of enterprise networks is fairly similar to the structure of the internet in general, with perhaps somewhat less of an emphasis on BGP security.
BGP in the datacenter underlay
Things are different in the datacenter. In large data centers, BGP has three different roles. First, there’s the “underlay”, the physical network that allows for moving packets between any server in any rack in the data center to any other server anywhere else, as well as to the firewalls and routers that handle external connectivity. Second, there’s often an “overlay” that creates a logical structure on top of the physical structure of the underlay. And third, BGP may be used by physical servers for routing packets to and from virtual machines (VMs) running on those servers.
It’s estimated that for each kilobyte of external (north-south) traffic, as much as 930 kilobytes of internal (east-west) traffic within the datacenter is generated. This means that the amounts of traffic that are moved within a large datacenter with many thousands of (physical) servers are absolutely massive. Internet-like hierarchical network topologies can’t support this, so data centers typically use a leaf-spine topology, as explained in our blog post BGP in Large-Scale Data Centers.
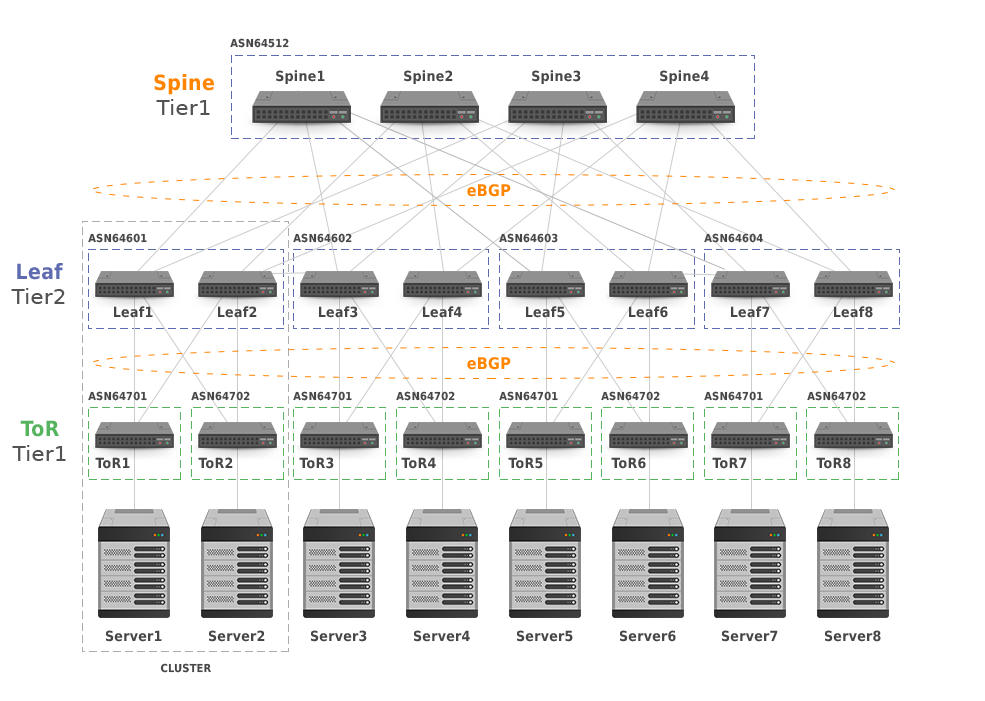 5-Stage Clos Network Topology with Clusters
5-Stage Clos Network Topology with Clusters
Even more so than in enterprise networks, in the datacenter underlay, BGP is used as an internal routing protocol. This means it would be useful for BGP to behave more like an internal routing protocol and automatically detect neighboring routers, rather than requiring neighbor relationships to be configured explicitly. Work on this has started in the IETF a few years ago, as discussed in our blog post BGP LLDP Peer Discovery, but so far, this work hasn’t yet been published as an RFC.
Another issue with such large scale use of BGP is that it requires a significant amount of address space to number each side of every BGP connection. An interesting way to get around this is the use of “BGP unnumbered”. Using BGP unnumbered with the FRRouting package (a fork of the open-source Quagga routing software) is well described in this book chapter at O’Reilly.
The idea is to set up BGP sessions towards the IPv6 link-local address of neighboring routers, and then exchange IPv4 prefixes over those BGP sessions. An IPv6 next-hop address is used for those prefixes as per RFC 5549. That doesn’t seem to make any sense at first: how can a router forward IPv4 packets to an IPv6 address? But the next-hop address doesn’t actually do anything directly. The function of the next-hop address is to be the input for ARP in order to determine the MAC address of the next hop. That very same MAC address can, of course, be obtained from the IPv6 next-hop address using IPv6 Neighbor Discovery. This way, BGP routers can forward packets to each other without the need for BGP to use up large numbers of IPv4 addresses.
BGP EVPN in the datacenter overlay
Many datacenter tenants have their own networking needs that go beyond the simple anything-to-anything IP-based leaf-spine model. So they implement an overlay network on top of the datacenter underlay network through tunneling. These can be IP-based tunnels using a protocol like GRE, or layer 2 run on top of a layer 3 underlay, often in the form of VXLAN.
VXLAN is typically implemented in the hypervisor on a physical server. This way, the VMs running on the same and different physical servers can be networked together as needed—including with virtual layer 2 networks. However, running a layer 2 network over a layer 3 network poses a unique challenge: BUM traffic. BUM stands for broadcast, unknown unicast and multicast. These are the types of traffic a switch normally floods to all ports.
To avoid this, VTEPs (VXLAN tunnel endpoints) / NVEs (Network Virtualization Edges) can use BGP to communicate which IP addresses and which MAC addresses are used where, along with other parameters, so the need to distribute BUM traffic is largely avoided. The VTEPs implement “ARP suppression”, which lets them answer ARP requests for remote addresses locally, so ARP broadcasts don’t have to be flooded by replicating them to all remote VTEPs.
RFC 7432 specifies “BGP MPLS-Based Ethernet VPN” and is largely reused for VXLAN. Originally, BGP could only be used for IPv4 routing, but multiprotocol extensions (also used for IPv6 BGP) allow BGP to be used to communicate EVPN information between VTEPs. Each VTEP injects the MAC and IP addresses it knows about into BGP so all other VTEPs. The remote VTEPs can then tunnel traffic towards these addresses to the next-hop address included in the BGP update. Unlike BGP in the underlay, which typically uses eBGP, EVPN information is transported over iBGP: all VTEPs/NVEs are part of the same AS. If there’s a lot of them, that means it’s helpful to use route reflectors to avoid having excessive numbers of iBGP sessions.
BGP and pods
In addition to the underlay and the overlay, there’s a third level of routing that’s becoming more relevant in the datacenter: the routing between “pods” on (virtual) hosts. Systems like Docker allow applications to be put into light-weight containers for easy deployment. A container is a self-contained system that includes the right versions of libraries and other dependencies. Unlike virtual machines, that each run a separate copy of an entire operating system in their own virtualized environment, multiple containers run side-by-side under a single copy of an operating system. Containers can do a lot of their own networking, but typically just run as a service under a TCP or UDP port number on the (virtual) host’s IP address.
However, this sharing of the host’s IP address makes it awkward to deploy multiple instances of the same application or service, as these tend to expect to be able to use a well-known port number. Kubernetes solves this issue by grouping together containers inside a pod. Pods are relatively ephemeral, and the idea is to run multiple pods on the same (virtual) machine. Containers in a pod share an IP address and a TCP/UDP port space. Within a Kubernetes deployment, all pods can communicate with each other without using NAT.
A pod’s network interface(s) can be bridged to the network interface(s) of the host on layer 2, and thus directly connect to the layer 2 or layer 3 service provided by an overlay network. However, this is not the most scalable solution. The alternative is to have the host operating system route between its network interface(s) and the pods that are running on that host. In this situation, pods will typically be provisioned with some IP address space from for instance etcd. In order for other pods and the rest of the world to reach the pod, these addresses must be made available in a routing protocol. Here BGP again has the advantage due to its flexibility, as shown in this blog post at Cloud Native Labs and this blog post over at Flockport.
Conclusion
BGP is undoubtedly one of the most sophisticated IP routing protocols deployed on the Internet today. Its complexity is primarily due to its focus on the routing policies. The generic statement that BGP only gets used when there is a need to route between two autonomous systems is quite misleading. There are multiple scenarios in which one may choose to use the protocol, or it might even be required. BGP remains the right tool for so many jobs!