Previously, we’ve already looked at traffic engineering in general and AS path prepending in particular. Traffic engineering is distributing the traffic load over available lines in order to utilize those lines most efficiently. For instance, if you have two 1 Gbps links and 1.4 Gbps worth of traffic, then, everything else being equal, you’d want 50% of the traffic to go over one link and 50% over the other. Maybe 65%/35% (910/490 Mbps) would still be ok, but what if BGP decides to send 75% of the traffic over one link and 25% over the other? That would be 1050 Mbps (well, really only 1000 Mbps, of course) over one link and 350 Mbps over the other. So now you’re using only 1.35 Gbps of the 2 Gbps you pay for and 75% of your traffic is suffering congestion. Not a good deal. By prepending BGP AS paths that include the link that attracts too much traffic, BGP will deem the previously overused link less attractive and start sending more traffic over alternative paths that include the underused link.
Previously, we’ve already looked at traffic engineering in general and AS path prepending in particular. Traffic engineering is distributing the traffic load over available lines in order to utilize those lines most efficiently. For instance, if you have two 1 Gbps links and 1.4 Gbps worth of traffic, then, everything else being equal, you’d want 50% of the traffic to go over one link and 50% over the other. Maybe 65%/35% (910/490 Mbps) would still be ok, but what if BGP decides to send 75% of the traffic over one link and 25% over the other? That would be 1050 Mbps (well, really only 1000 Mbps, of course) over one link and 350 Mbps over the other. So now you’re using only 1.35 Gbps of the 2 Gbps you pay for and 75% of your traffic is suffering congestion. Not a good deal. By prepending BGP AS paths that include the link that attracts too much traffic, BGP will deem the previously overused link less attractive and start sending more traffic over alternative paths that include the underused link.In most cases, a single prepend is very effective at changing traffic flows. However, each additional prepend quickly becomes less effective than the previous one, and some traffic just won’t budge, no matter how long the path gets. Later in this post we’ll look at some issues with overly long AS paths, but first, let’s try to understand the effectiveness of different amounts of AS path prepending.
Over time, the connections between the networks that make up the internet have been getting denser. Currently, the average AS path length seen at well-connected points in the network is about 4.5 AS hops, and half a hop less if we ignore prepending. Because there are now so many direct connections between transit ASes, that means that very often, the number of AS hops over different paths is the same. A random sample of information collected by the RouteViews project shows that for any two transit networks that share their BGP information with RouteViews, in most cases, more than 75% of AS paths are the same length.
This has the result that if we prepend towards one of these transit networks, at least 75% of destinations now see a longer path over the prepended path and thus a shorter path over the unprepended path. Which in turn has the result that a massive amount of traffic moves from the prepended path to the unprepended path. So it’s not uncommon for one prepend to be too effective.
Note that this only applies for traffic engineering incoming traffic. If a network only announces a single prefix towards the rest of the world, that prefix can either be prepended towards a certain BGP neighbor or not. If a network announces more prefixes, it can prepend some of these and not others. As all networks receive large numbers of announcements it’s easy to selectively prepend those to achieve fine-grained traffic engineering for outgoing traffic.
Let’s have a look at the good, the bad and the ugly of AS path prepending.
The good: when prepending works
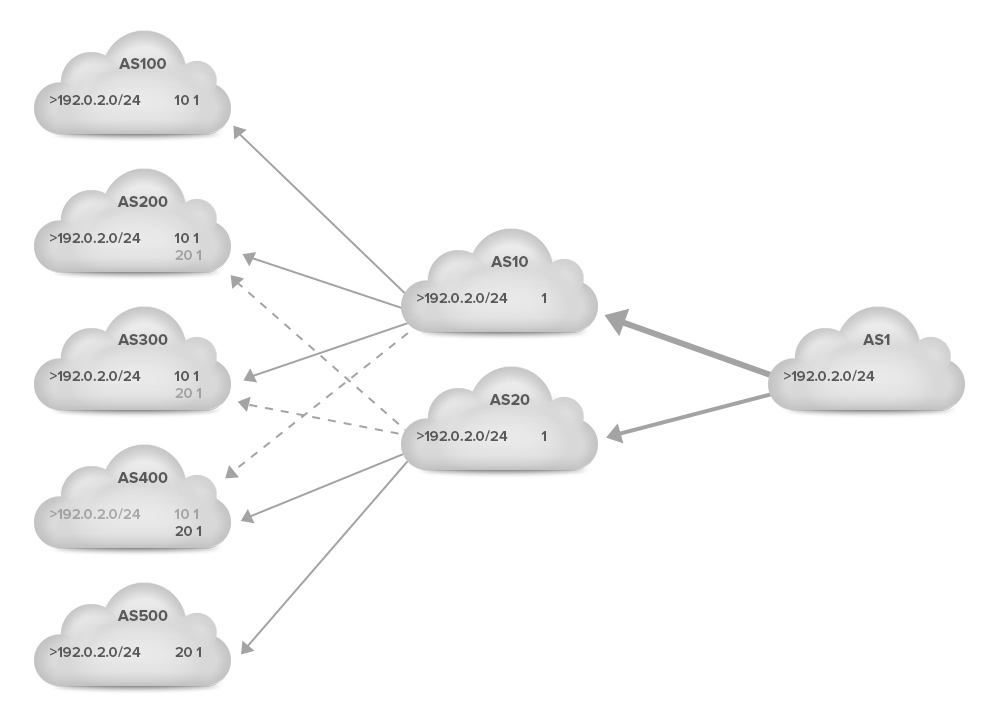
For everyone to understand how prepending works, let’s take a look at the following simplified example. A network with eight autonomous systems is presented in the figure below. ASes 10 and 20 are transit providers that provide connectivity to ASes 1, 200, 300 and 400. AS 10 also provides transit service to AS 100 and AS 20 to AS 500.
AS 1 on the left advertises the prefix 192.0.2.0/24, which is propagated by ASes 10 and 20 to their customers on the left. Each time an AS announces the prefix to the next AS, it adds its own AS number to the left side of the existing AS path.
As a result, ASes 200, 300 and 400 now have two options to reach 192.0.2.0/24: 10 1 through AS 10 or 20 1 through AS 20. In this example, the BGP tie-breaker rules make ASes 200 and 300 prefer the path through AS 10 and AS 400 the path through AS 20. (This is indicated by the > character in front of the preferred paths.) ASes 100 and 500 use the only path they have available, through AS 10 and AS 20, respectively.
The result is that traffic from ASes 100, 200 and 300, as well as traffic from AS 10 arrives at AS 1 through the link to AS 10. Traffic from ASes 400, 500 and 20 arrives through AS 20. So the traffic split is 4 : 3 (57% : 43%). (For simplicity, we’ll assume that each AS generates the same amount of traffic towards AS 1.)
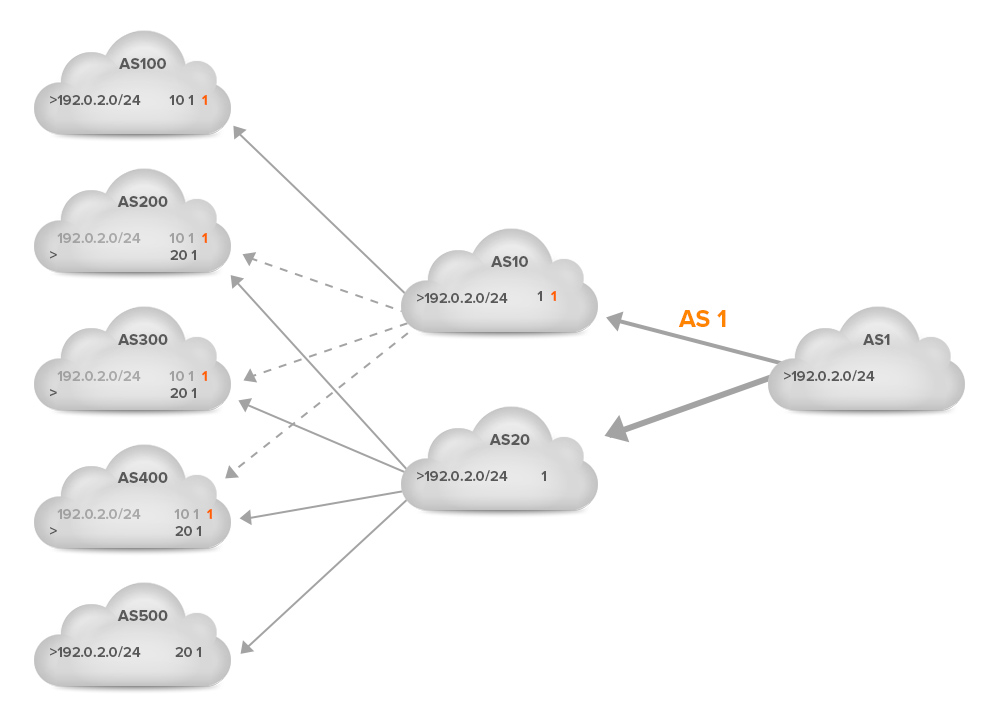
 Now suppose the link towards AS 20 has more capacity or is cheaper to use than the link to AS 10. So AS 1 wants to receive more traffic through AS 20 and less through AS 10. In order to achieve this, AS 1 adds an extra copy of its AS number (prepends) to the left side AS path of the announcement of the prefix 192.0.2.0/24 towards AS 10. This is shown in the next figure. The solid lines indicate preferred paths, the dotted lines paths aren’t used because another path is preferred.
Now suppose the link towards AS 20 has more capacity or is cheaper to use than the link to AS 10. So AS 1 wants to receive more traffic through AS 20 and less through AS 10. In order to achieve this, AS 1 adds an extra copy of its AS number (prepends) to the left side AS path of the announcement of the prefix 192.0.2.0/24 towards AS 10. This is shown in the next figure. The solid lines indicate preferred paths, the dotted lines paths aren’t used because another path is preferred.
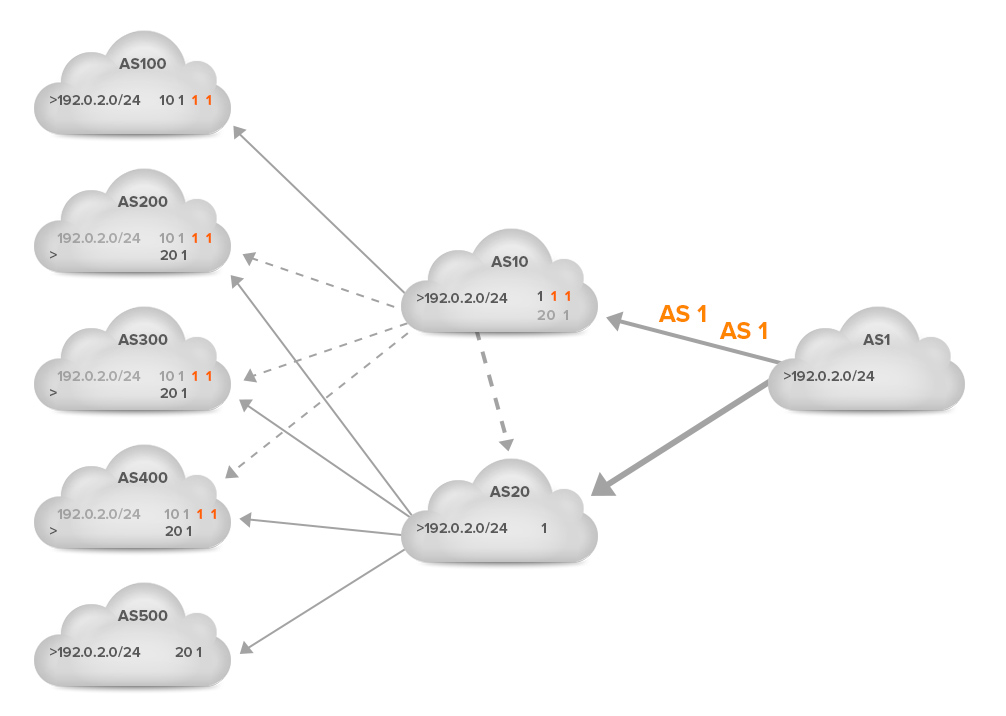
 ASes 100, 200, 300 and 400 now see the AS path 10 1 1 where they saw AS path 10 1 before. In the case of ASes 200, 300 and 400, this means that the path 20 1 is now shorter, so ASes 200 and 300 now switch to using the 20 1 path. (AS 400 was already using this path.) The result is that now only ASes 10 and 100, which don’t have any other options, send their traffic through the AS 10 – AS 1 link. All other ASes send their traffic through the AS 20 – AS 1 link. This makes the traffic split ratio 2 : 5 (29% : 61%). So this was a very effective prepend, as it moved 28% of traffic from the 10-1 link to the 20-1 link.
ASes 100, 200, 300 and 400 now see the AS path 10 1 1 where they saw AS path 10 1 before. In the case of ASes 200, 300 and 400, this means that the path 20 1 is now shorter, so ASes 200 and 300 now switch to using the 20 1 path. (AS 400 was already using this path.) The result is that now only ASes 10 and 100, which don’t have any other options, send their traffic through the AS 10 – AS 1 link. All other ASes send their traffic through the AS 20 – AS 1 link. This makes the traffic split ratio 2 : 5 (29% : 61%). So this was a very effective prepend, as it moved 28% of traffic from the 10-1 link to the 20-1 link.
The bad: when prepending stops working
However, what if the effect of one prepend wasn’t enough, and AS 1 wants to move even more traffic from the 10-1 link to the 20-1 link? The next figure shows another prepend:
 But: there is no change. Even if we make AS 10 a customer of AS 20, so that AS 10 has a two-hop path towards AS 1 through AS 20 (20 1), AS 10 still prefers the direct path, even though the AS path is three hops: 1 1 1. The reason for this is that before considering the AS path, most networks, and certainly the larger ones, look at the business relationship they have with external ASes.
But: there is no change. Even if we make AS 10 a customer of AS 20, so that AS 10 has a two-hop path towards AS 1 through AS 20 (20 1), AS 10 still prefers the direct path, even though the AS path is three hops: 1 1 1. The reason for this is that before considering the AS path, most networks, and certainly the larger ones, look at the business relationship they have with external ASes.
Once research on BGP started, it became clear that there can be situations where BGP won’t converge to a stable state. But then a seminal research paper by Lixin Gao and Jennifer Rexford showed that BGP will, in fact, reach a stable state as long as network operators observe a set of guidelines, which boil down to:
- prefer routes learned from customers over routes learned from peers
- prefer routes learned from peers over routes learned from transit providers
In practice, this is implemented by giving routes learned from customers a high local preference (say, 200), routes learned from peers an intermediate local preference (say, 150) and routes learned from transit providers the lowest local preference (say, 100). This way, the BGP path selection algorithm will come up with results that conform to the Gao/Rexford guidelines.
The guidelines make perfect business sense, as sending traffic to a customer makes money, sending it to a peer is free and sending it to a transit provider costs money.
But the result is that, no matter how many times you prepend a path towards your service provider, you’ll still get traffic that originates within that service provider’s network as well as traffic from their customers who have no other transit providers. And also from remote ASes that have set up their traffic engineering such that your long path is overruled by an even longer path, or, more likely, a local preference setting.
If this is a problem, see if your transit provider lets you set up an active/standby configuration using communities.
The ugly: when prepending creates problems
An unsolved issue with BGP security is networks announcing prefixes without authorization. When this happens accidentally, it’s called a route leak. This is often caused by networks failing to implement filters that go with a certain business relationship. For instance, when network A peers with networks B and C, and then propagates the prefixes from B to C. This is to be expected when B pays A to receive (and send) traffic from the rest of the world (A is B’s transit provider), or when B pays A to advertise B’s prefixes to the rest of the world (A is B’s transit provider). But if A is neither B’s nor C’s transit provider, it shouldn’t provide transit service anyway.
Such a route leak is always a bad situation, as it lets traffic flow over an unexpected and likely untrusted path, and that path will usually not have the capacity to handle all the extra traffic. However, traffic will only flow over the leaked paths if those are shorter than the shortest regular path. So when AS paths are nice and short, route leaks are less likely to be a problem. With every prepend, the potential impact of a route leak increases. Fortunately, most networks rarely encounter route leaks, so completely foregoing AS path prepending even in situations where it could be very useful, would probably be an overreaction. But it’s best to err on the side of minimal AS path prepending to limit vulnerability to route leaks.
Last but not least, there’s AS path filtering. Some networks filter excessively long AS paths. In a way, this is similar to filtering on prefix length, where IPv4 prefixes longer than /24 and IPv6 prefixes longer than /48 are filtered out by many networks. However, no such convention exists for maximum AS path lengths. One network operator mentioned filtering out prefixes with AS paths longer 20 hops. Since the hop count increases as a prefix makes its way from one AS to the next, it’s important to apply a healthy safety margin. As more than 99.9% of AS paths are 10 hops or less (without prepends), 10 prepends and a 10 hop safety margin should slide in just under the 20 hop limit that apparently at least one network filters on.
However, due to the rapidly declining effect of additional prepends, it may be best to avoid applying more than three prepends anyway.