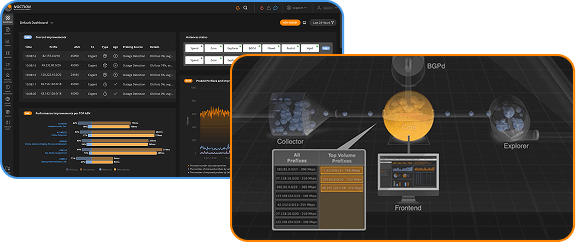
As discussed in earlier posts, as networks grow larger it starts making sense to exchange traffic with other networks directly (peering) rather than pay one or more big ISPs to handle all your internet traffic (transit). When you start peering, you’ll have to figure out what your peering policy should look like.
As discussed in earlier posts, as networks grow larger it starts making sense to exchange traffic with other networks directly (peering) rather than pay one or more big ISPs to handle all your internet traffic (transit). When you start peering, you’ll have to figure out what your peering policy should look like.When you first start peering over a single internet exchange (IX), it’s very simple. Your IX connection has a relatively high fixed monthly cost, but no metered per-megabit costs. So once you take the plunge and connect on an internet exchange, you’ll want to fill up that circuit as much as possible and save money on metered transit circuits. You adopt an open peering policy and peer with anyone. Your peering policy only has some “sanity checks”, such as the following:
- Public AS number and public address prefix(es) (i.e., not RFC 1918 addresses)
- Network Operations Center (NOC) reachable 24/7
- Notifications for maintenance and outages
- No pointing of static and/or default routes
A malicious peer could point a default route or other static route towards your router and thus route their traffic through your network without your permission.
Things get more complex when you start peering in multiple locations. Suppose networks X and Y peer in Los Angeles and Washington, DC. If now user A, who is a customer of X in LA, sends traffic to user B, who is a customer of network Y in LA, obviously the traffic will flow through the peering point in LA—in both directions. Similarly, traffic between A (X-DC) and B (Y-DC) flows through the peering point in DC. But what when A (X-LA) sends traffic to B (Y-DC)?
The default behavior of BGP in this situation is early exit or hot potato routing: the traffic is handed over to the destination network at the earliest opportunity. So the traffic from user A in LA towards all destinations in network Y will be handed over to Y in LA. However, network Y also uses early exit routing, so the return traffic from B will be handed over to network A in DC. So each network has to carry incoming traffic long distance, but gets to hand over outgoing traffic locally or regionally.
This works well if traffic volume in both directions is about the same. However, that’s rarely the case: most networks either serve consumers, who generate very little outgoing traffic, but do consume a lot of incoming traffic, or they serve mostly content providers, which have very little incoming traffic, but lots of outgoing traffic. If the two types of network peer in multiple locations, the content network gets a free ride: they can hand over their large outgoing traffic streams locally, and only have to build out a modest long-distance network to carry the small amount of incoming traffic. “Eyeball” networks (serving consumers looking at web pages and online video) on the other hand, need to build out very large long distance infrastructures to handle all that incoming traffic delivered to them at inconvenient locations.
As a result, networks carrying a lot of incoming traffic typically require a balanced traffic ratio. Such a policy could be described as a selective peering policy. However, this means that you won’t be peering with networks that send you (much) more traffic than you send them. If you still want to peer with those networks, but without having to bear the burden of most of the long distance transport, you need to configure BGP—and possibly talk to your peer—so traffic is no longer handled in early exit fashion.
In these cases, the notion of “megabit kilometers” or “bit miles” or similar can be a guide. You don’t want to go down the rabbit hole of figuring out the geographic path for every packet that you exchange with a potential peering partner. However, obviously if a content provider on the US East Coast wants to send a gigabit worth of traffic to your customers on the West Coast through a peering point in DC or NYC, that’s not a very equitable arrangement. On the other hand, if that same content provider is located in Europe and the traffic is exchanged in DC or NYC, you’re both carrying the traffic approximately the same distance.
On the third hand, consumers are tied to a specific location, while large content networks are typically flexible with regard to where they source large traffic flows. So it’s not unreasonable for an eyeball network to require that large amounts of incoming traffic are handed over at the peering point closest to the consumer. Technically, you can accomplish this in two ways: the “hard” and the “soft” method.
The “hard” method is to simply only announce local/regional prefixes at any peering point. If you only announce the prefixes used by customers in California in LA and prefixes used in Virginia in DC, then you can peer with content networks without having to worry about them (ab)using your long distance capacity. However, the disadvantage of this is that if there’s an outage in one region, traffic will not be rerouted through another region. So you have to make sure you have sufficient redundant paths in each region.
The “soft” method is to announce all your prefixes everywhere, but manipulate the BGP attributes such that BGP uses “late exit” or “cold potato” routing. The most straightforward way to do this is to announce prefixes that are local/regional to a peering point with a lower MED at that peering point and with a higher MED at peering points in other regions. This way, when there’s an outage, traffic can still be rerouted over peering points outside the region.
However, in this case, make sure that your peering partners honor your MEDs. You may want to require this in your peering policy and make sure your peers don’t say the opposite in theirs—some networks do. Also, some networks require that your BGP advertisements are consistent throughout all common peering points. Ultimately, if one network insists on early exit and the other on late exit routing, the two networks can’t peer.
The “hard” method of only announcing regional prefixes makes it possible to peer with local/regional networks in a reasonably equitable way, but the “soft” method using MED manipulation doesn’t: the small network sees all of your prefixes only in one region, so they’ll hand over traffic to all parts of your network in that region and you’ll have to carry it long distance. So if you depend traffic ratios on “soft” late exit routing, you may want to require that peering happens in a certain minimum number of regions.
As your network grows, you may also no longer want to peer with very many small networks, because the work involved in setting up and monitoring the peering isn’t worth the relatively low amount of traffic you get to exchange—especially if you peer with those networks’ transit providers anyway. To achieve this, you can require peering in multiple locations and/or require a certain minimum traffic flow. In the latter case, you’ll need to set up Netflow so you can monitor how much traffic flows to/from (potential) peering partners. You should still be able to peer with smaller networks through route servers, if desired.
Public peering over an internet exchange is relatively simple, because each party pays for their own connection to the exchange. However, as traffic volumes increase, it starts making sense to peer over a direct circuit and cut the IX out of the loop. However, this adds the complication of having to negotiate who pays for the circuit between your router and theirs. Also, it can be useful to require a certain upgrade regime, as networks may hold off on upgrading oversubscribed peering circuits for various reasons.
If you provide transit service, you may encounter the situation where a customer leaves and then wants to peer with you. A common restriction in the peering policy of larger networks is that a peer hasn’t been a customer recently or isn’t a customer of an existing peer or customer.
The question on whether a peering contract is useful is best answered by a lawyer. In practice, most public peering happens without one. Some networks require an MD5 password on BGP sessions; some have hardware that doesn’t support this or don’t want to use MD5 password for another reason. Most networks will use a password if desired by a peer, but don’t insist on one. Without an MD5 password (or the GTSM security mechanism), your BGP sessions may be vulnerable to TCP reset attacks. This is not a huge deal for BGP sessions that carry small numbers of prefixes, but it becomes more problematic as sessions carry more prefixes. So you may want to use MD5 for larger peers sending many prefixes.
Obviously, it’s tempting to make all of this up as you go along, and it makes sense to include a clause in your peering policy stating that you can make exceptions to your stated policy. On the other hand, peering is receiving more scrutiny these days, and applying a consistent policy helps minimize the potential for disputes, which are more likely as a network adopts a restrictive peering policy in order to further its business goals.
These are some examples of peering policies: