

 Flow-based (NetFlow, IPFIX, NetStream) and packet-based (sFlow) network monitoring technologies enable network administrators to gain insight into traffic traversing a network. They provide various statistical information such as top talkers, applications in use, general utilization, the needed for detection of network anomalies, QoS, billing, future network planning, etc.
Flow-based (NetFlow, IPFIX, NetStream) and packet-based (sFlow) network monitoring technologies enable network administrators to gain insight into traffic traversing a network. They provide various statistical information such as top talkers, applications in use, general utilization, the needed for detection of network anomalies, QoS, billing, future network planning, etc.In general, one of the fundamental requirements of network monitoring is accuracy in terms of estimation of traffic parameters. Ideally, all flow-monitoring technologies should provide 100% accuracy. In reality, accuracy is degraded by a certain way of data reduction in order to address scalability issues. Sampling is one of the effective methods used for reduction of the collected data exported to flow collector and it is equally implemented in both flow-based and packet-based monitoring technologies.
Routers and switches function as embedded monitoring probes and do not have enough computing power to monitor network traffic on high-speed links as their primary concern is packet forwarding. If every packet was captured and its statistic recorded into flow, too much CPU power, flow cache memory and network bandwidth would be consumed in order to record, store and export flows to the flow collector. On one hand, optimal packet sampling is a method that effectively reduces the measurement overhead in context of device’s resource usage and bandwidth consumption for flows export. On the other hand, excessive sampling should be avoided as it increases the amount of exported flow data, especially on the high-speed links, where the network traffic volume is high. Let’s have a look at a situation where sampling is done on a packet count level and there are 11 short flow sessions, each counting 100 packets. If the sampling rate is 1:1024 then every 1024th packet is sampled and used for the flow state update. While unsampled NetFlow generates 11 flow records in a row, the sampling rate 1:1024 results in a single flow record. Flow update rate is reduced to 1/11th, not 1/1024th.
The original sampled NetFlow feature implemented for Cisco 12000 series uses the systematic sampling with the count-based triggered periodic selection of every k-th packet. The majority of the packets are switched faster because they do not need to go through additional NetFlow processing. The sample packets will be accounted by the NetFlow cache on the router. Sampled NetFlow implemented in the Cisco Nexus 5600 series (NX-OS) supports random sampling mode, M out of N (M:N), where M packets are selected randomly out of every N packets for sampling, and only those packets can create flows. According to a study “On the Accuracy and Overhead of Cisco Sampled NetFlow“, the Sampled NetFlow performs correctly without significant overhead under load and the overhead is indeed linearly proportional to the number of flows recorded. The study also compares the performance of both systematic and random samplings employed in the different Sampled NetFlow versions. The experiments confirms that the performance of both sampling technologies is similar (see the graph below).
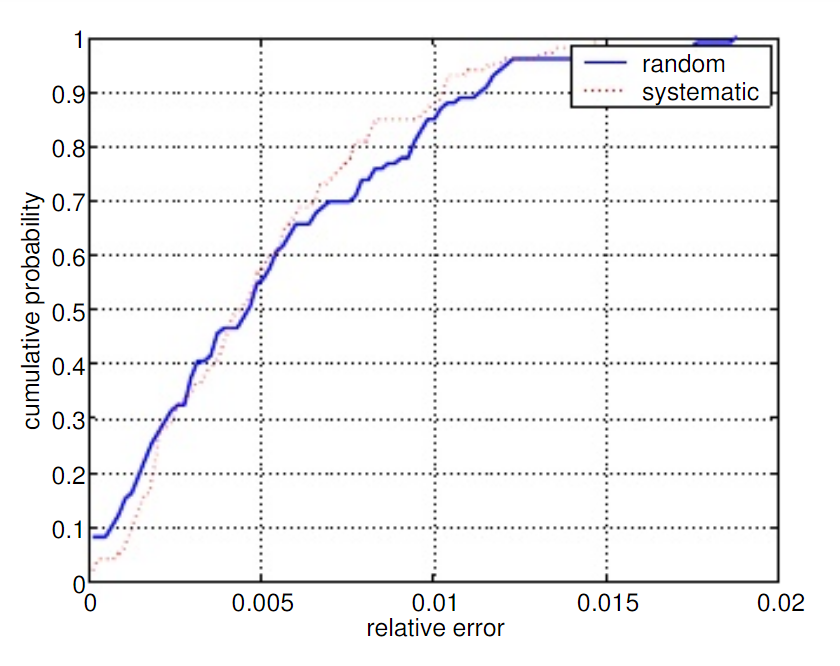
The number of the Sampled NetFlow export packets
One can suggest that multiplying the measured data count with the sampling rate on the netflow collector provides an approximation of the actual traffic rate. In fact, the sample multiplier is applied to the sampled traffic, not all of the traffic. The accuracy of estimation depends on the characteristics of traffic as well as the number of samples. In many cases conversations may not show up at all in the report details because they did not get sampled. This is very much the case on high volume devices where the minimum sample rates are in thousands. On the other hand, there are lots of very short conversations of only a couple of packets that do not get sampled as well. For instance, in case of a successful TCP SYN port-scan, there are only 3 packets exchanged between an attacker and a victim (the TCP flags are SYN, SYN-ACK, RST). It is very likely this type of “conversation” becomes invisible for the majority of traffic analysis applications out there and the attack goes undetected, because the packets are not sampled thus accounted for the update of the NetFlow cache. This traffic is “lost” in a regular user traffic due to its nature. It is very much a case when an attacker adjusts a longer scan delay interval between probes.
Denial of Service (DoS) attacks are conducted with the aim of overwhelming the victim infrastructure and denying access to a legitimate user. In case of a Distributed DoS (DDoS) attack, a large numbers of compromised systems are directed to send traffic to a victim. DDoS attacks can be successfully detected when sampling is used, looking at the overall flow volume to see if a spike occurs, tracking down source and destination L4 ports, IP addresses, TCP flags etc. The accuracy of detection depends on the sampling rate. With the higher sampling, e.g. 1:50 000 flows, the error in the DDoS analysis becomes much bigger. The bigger the sampling rate, the bigger the deviation needs to be to confidently say that there is a DDoS happening.
Conclusion:
Packet sampling mechanisms are definitely a must on the high-speed links in order to scale high data volumes. This is the reason why sampling feature was added to a non-sampled NetFlow version. Other packet and flow based network monitoring technologies such is sFlow, IPFIX, NetStream support packet sampling as well. What is important to say is that sampling in most cases sacrifices monitoring accuracy for router performance. While the acceptable accuracy works great for a real-time detection of network anomalies caused by DDoS attacks, accurate network forensics requires full flow records in order to track every communication. So, in scenarios where accuracy is the main concern, it is better to avoid sampling, however when robust and a better scalable solution is needed, sampling is a necessary evil.


