OSPF and BGP: Differences and Interactions
OSPF and BGP: Differences and Interactions
 OSPF and BGP: Differences and Interactions
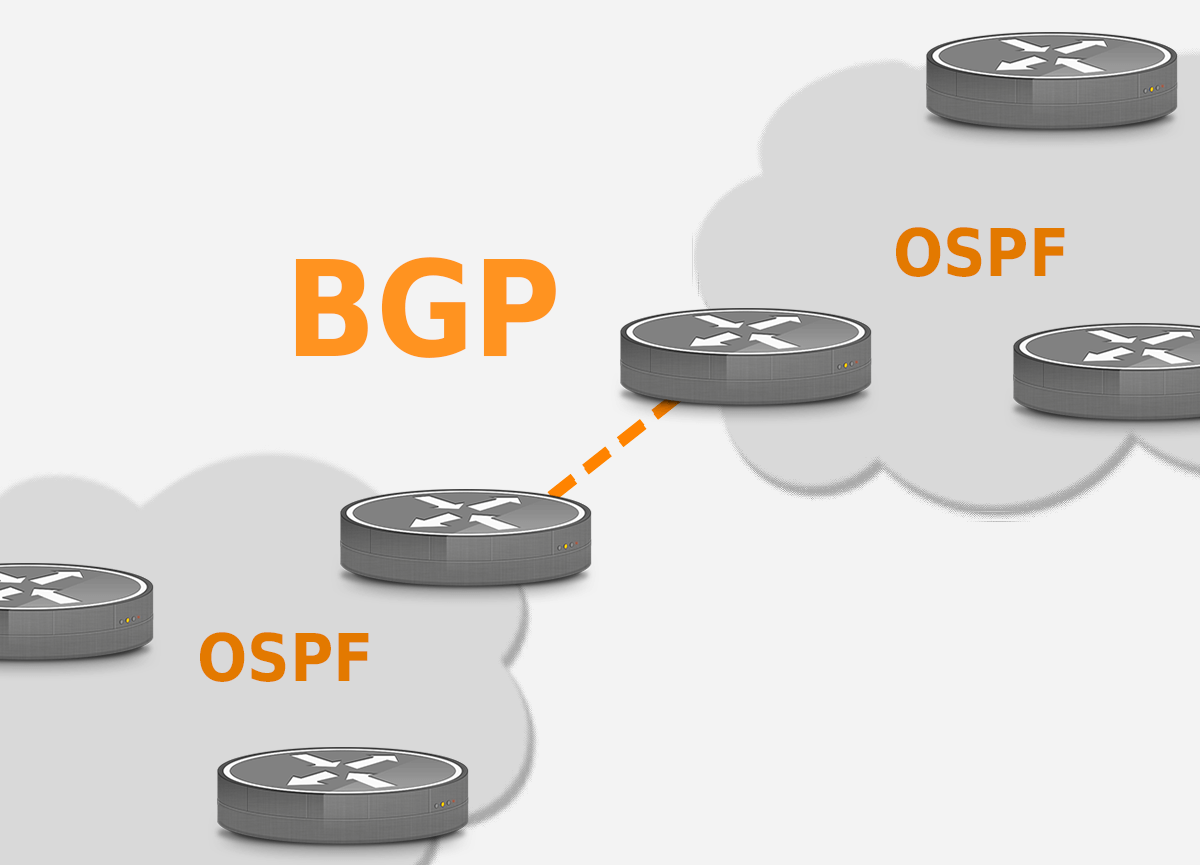
OSPF and BGP: Differences and InteractionsWhen it comes to routing protocols, two of the most popular are OSPF (Open Shortest Path First) and BGP (Border Gateway Protocol). Both OSPF and BGP are used to determine the best path for data to travel through a network, but they do so in very different ways. In this article, we will discuss the differences between BGP and OSPF, when to use each protocol, and how they can be used together.
Understanding BGP as an Exterior Gateway Protocol
BGP is an Exterior Gateway Protocol (EGP) that is used to connect different autonomous systems (ASes) together. It is a path-vector routing protocol that allows routers to exchange information about the paths to reach different destinations. This particular protocol has several advantages over other routing protocols, including its ability to handle complex routing policies, its support for multiple paths to the same destination, as well as support for route filtering and manipulation.
In some ways, BGP is nice and simple. For instance, there’s only one BGP: BGP version 4. Many network professionals have been asking the question of whether BGP version 4 will soon be replaced by BGP 5. However, there is nothing to worry about. We still run BGP version 4 as our Exterior Gateway Protocol. Today’s BGP4 does all kinds of things that the BGP4 from 20 years ago couldn’t do, such as routing IPv6, multicast, and VPNs or using communities. BGP has shown itself to be very extensible, but it’s all still BGP—and a single BGP process at that. But BGP only handles the exterior side of routing—there’s also interior routing.
Understanding OSPF as an Interior Gateway Protocol
There’s a lot more choice in Interior Gateway Protocols (IGPs). An old favorite is RIP, the Routing Information Protocol. Even the improved RIPv2 is too simple for most networks these days, as is RIPng (next generation) for IPv6. As such, Cisco created its own Interior Gateway Routing Protocol (IGRP) and then an enhanced version aptly named Enhanced IGRP (EIGRP). However, the most widely used IGP is OSPF: Open Shortest Path First.
OSPF is a link-state routing protocol that allows routers within a single AS to share information about the network topology and calculate the shortest path to each destination using an “open” implementation of the Shortest Path First or Dijkstra’s algorithm. (The name doesn’t refer to the possible openness of the shortest path.)
OSPF supports a hierarchical network topology, where routers are organized into areas, and each area has its own set of routers. Each router within an area maintains a link-state database that contains information about the topology of the network. The link-state database is used to calculate the shortest path between two points using the Dijkstra algorithm.
One of the key features of OSPF is its fast convergence rate. Convergence is the time it takes for routers to agree on the best path for data to travel through the network. With OSPF, convergence is typically very fast, which is important in large networks where routing changes can occur frequently. OSPF also supports load balancing, allowing traffic to be distributed across multiple paths to improve network performance.
OSPF has several advantages over other routing protocols, including its support for variable-length subnet masks (VLSMs), its ability to support multiple equal-cost paths, and its support for route summarization. OSPF is easy to configure, and it is widely supported by networking vendors.
OSPF version 2 is used for IPv4; OSPF version 3 for IPv6. Networks that run both IP versions and use OSPF as their IGP thus need to run both OSPFv2 and OSPFv3.
Interesting Fact: Back in the late 1980s, when OSPF was developed, the OSI (Open Systems Interconnect) family of networking protocols was still in contention, and a lot of technology was borrowed/stolen by OSI from IP and by IP from OSI. As a result, OSI has the IS-IS routing protocol for OSI CLNP routing, which is very similar to OSPF in many ways (or the other way around). IS-IS stands for Intermediate System to Intermediate System, where “intermediate system” means “router”. IS-IS was later extended to support first IPv4 and then also IPv6 and is mainly used in very large IP networks.
What are the major differences between OSPF and BGP?
The decision to use OSPF or BGP depends on various factors, such as the size and complexity of the network, the number of autonomous systems involved, and the routing requirements.
OSPF is best suited for small to medium-sized networks with a hierarchical topology. It provides fast convergence rates, is easy to configure and manage, and is ideal for networks that require quick routing updates. OSPF is a good choice for networks that require equal-cost path load balancing, as it supports this feature by default.
BGP, on the other hand, is designed for large-scale networks. It provides slower convergence rates, is more complex to configure and manage, and is ideal for networks that require policy-based routing. BGP is a good choice for networks that require path selection based on various attributes such as AS path length and local preference.
Here are some major differences between OSPF and BGP that one needs to know about:
OSPF | BGP | |
Protocol type | Link-state protocol | Path-vector protocol |
Scope of usage | Used within a single AS | Used between ASes |
Network size handling | Hierarchical routing | Can handle very large and complex networks |
Routing metric calculation | Routes based on multiple metrics, including bandwidth, delay, and reliability | Routes based on policy decisions made by the network administrator |
Convergence time | Converges quickly and adapts well to network changes | Slower convergence and less adaptable to changes |
Usage scenario | Typically used for internal routing within an organization's network | Typically used for routing between different organizations or ISPs |
Routing information exchange mechanism | Uses multicast to distribute routing information | Uses unicast to exchange routing information |
Security features | Supports authentication and encryption of routing information | Supports authentication but may require additional measures for encryption of routing information |
Equal-cost multipath (ECMP) routing support | Can be used with equal-cost multipath (ECMP) routing | Can be used with ECMP routing, but requires careful management to avoid routing loops |
Memory and processing power requirements | Requires more memory and processing power for large networks | Requires less memory and processing power for large networks |
Scalability | May not scale well for very large networks | Designed to scale to support very large networks |
Configuration complexity | Generally less complex to configure and maintain | Can be more complex to configure and maintain |
Routing control | Provides more granular control over routing within an AS | Provides more flexibility for routing between ASes |
Trust between routers | Generally better suited for network environments with high levels of trust between routers | Better suited for network environments with lower levels of trust between routers |
With the above introductions out of the way, let’s focus on the most common case: a network running BGP as the EGP and OSPF as the IGP and look at how the routing duties are divided over both protocols and how the two interact.
OSPF Route Redistribution
With OSPF being an IGP and BGP being an EGP suggests an obvious division of labor: OSPF handles the internal routing, BGP the routing towards external destinations. However, it’s not that simple. Yes, OSPF is in charge of internal routing. These routes show up as “O” routes in the output of “show ip route” on a Cisco router. If the network is split into multiple OSPF areas—not really necessary these days unless you have hundreds of routers—you may also see inter-area “O IA” routes.
O and O IA routes are only the address blocks that are used on router interfaces that actually run OSPF. That doesn’t include interfaces towards servers or PC’s and other end-user devices, or, in the case of ISPs, customers. To make those addresses show up in OSPF, we need to redistribute connected subnets and/or redistribute static routes:
! router ospf 1 redistribute connected subnets redistribute static subnets !
The 1 in “router ospf 1” is the OSPF process or instance number. It’s possible to run multiple OSPF instances on the same router—which, of course, requires careful planning to keep everything straight. If redistribution of all connected and/or static routes in OSPF is more than you need, you can add “route-map
By default, redistributed routes are made external type 2 and show up as “O E2”. It’s also possible to redistribute as external type 1 (with “metric-type 1”). The difference is that with O E1 routes, the OSPF cost of the route includes the cost of the links to reach the external route, while with O E2 routes, the cost of the internal links is ignored.
iBGP intricacies
Obviously, BGP handles the routes towards external networks that are BGP-capable. However, it would be a bit embarrassing if all the BGP routers in the network were telling their external neighbors completely different things. So all the BGP routers in the network need to talk to each other in order to tell a consistent story to external networks. This is what internal BGP (iBGP) is for. The “regular” BGP is thus external BGP (eBGP). When we say all the BGP routers, we really do mean all of them: if your network has 100 BGP routers, each of those needs to maintain iBGP sessions with the other 99. Well, unless you use route reflectors, but that’s a story for another day.
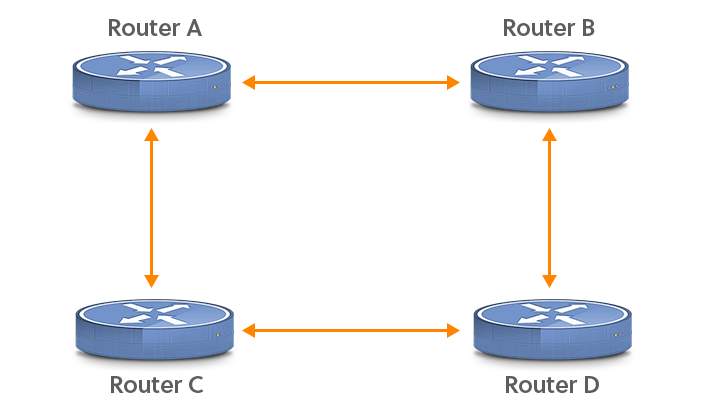
If you’re used to eBGP, iBGP requires some time to get accustomed to. Unlike eBGP, iBGP is just fine working over many hops. However, this adds a complication. Consider the following network:
! interface loopback0 ip address 192.0.2.65 255.255.255.255 ! router bgp 9000 neighbor 192.0.2.67 remote-as 9000 neighbor 192.0.2.67 update-source loopback0 !
Unlike other interfaces, loopback interfaces can have a /32 prefix length, so they only use up a single address. The remote AS for neighbor 192.0.2.67 is the same as the local AS (9000), making this BGP session an iBGP session. The “update-source loopback0” line makes sure that the source address in outgoing BGP packets is the IP address configured on interface loopback0, so it matches the address the remote router is looking for. If one path between the two iBGP routers goes down, the iBGP packets can be rerouted over another path and there’s no impact on BGP. Note that for this to work, the loopback interface addresses need to be present in the IGP—typically, connected routes will be redistributed to make this happen.
Also unlike eBGP, iBGP doesn’t update the AS path or the next hop address. This means that the next hop address in iBGP updates still points towards the IP address of the router in the neighboring network that the route was learned from. This address will reside in a point-to-point subnet between your eBGP router and the BGP router of the neighboring network. Your eBGP router will know this address because it’s present on a directly connected interface, but without further action, the rest of your routers won’t know this address, so the next hop address for iBGP routes won’t resolve, and the iBGP routes can’t be used. Again, redistributing connected networks into OSPF (or your IGP of choice) solves this. Alternatively, you can configure “next-hop-self” on your iBGP sessions, and the router will replace the next hop address in iBGP updates with its own address.
BGP redistribution
It’s also possible to redistribute routes into BGP. For instance, in a large ISP network, you may redistribute connected and static routes in BGP rather than in IS-IS, because this will keep IS-IS lean and mean. The extra BGP routes are relatively inconsequential, and a nice benefit is that if they’re rerouted internally, this doesn’t trigger any BGP updates. Rather, the next hop addresses are resolved differently after an IS-IS change, which each router can do independently. Of course, doing this requires good filters that make sure that the large numbers of small prefixes used by customers don’t leak into the global BGP table. A good way to accomplish such filtering is by adding a community to the routes that may be propagated in eBGP and then filtering based on that community.
Back in the day, it wasn’t uncommon to redistribute all BGP routes into OSPF. With an enormous amount of prefixes in BGP, this practice has become less common. If you really want to live on the edge, you can redistribute BGP into OSPF and OSPF into BGP. Then, if your filters aren’t perfect, routes may round-trip between BGP and OSPF, with the result that the AS path gets removed. So now you’re advertising over BGP a whole bunch of routes that aren’t yours but with a one-hop AS path, so a lot of your neighbors will start sending you traffic for these routes.
Administrative distance
Last but not least, what happens when the same route is present in both BGP and OSPF? Obviously, it’s hard to compare a BGP local preference to an OSPF metric. So what a (Cisco) router does is assign an “administrative distance” to each routing protocol. The route with the lowest distance then wins. OSPF has a distance of 110. BGP routes have a distance of 20 (better than OSPF and other IGPs) when they’re learned over eBGP and 200 (worse than OSPF and other IGPs) when they’re learned over iBGP. Static routes have a distance of 1 by default, but you can change this by including a distance value at the end of the “ip route …” command. A distance value of 250 will keep them out of the way of routing protocols. The administrative distance is the first number between square brackets in the “show ip route” output.
Conclusion
OSPF and BGP are two of the most widely used routing protocols in computer networks. OSPF is an IGP that is best suited for hierarchical network topologies, while BGP is an EGP that is best suited for a mesh topology. The decision to use OSPF or BGP depends on various factors, such as the size and complexity of the network and the routing requirements. In some cases, it may be necessary to use both protocols together as a hybrid routing protocol to provide a scalable and efficient solution for routing traffic between multiple ASes.