When there is a change in the reachability of one or more prefixes, BGP needs to do some work to adapt to that change and reach a new stable state. This is called “BGP convergence”. How fast BGP converges and how much packet loss occurs during the convergence process depends on four conditions:
When there is a change in the reachability of one or more prefixes, BGP needs to do some work to adapt to that change and reach a new stable state. This is called “BGP convergence”. How fast BGP converges and how much packet loss occurs during the convergence process depends on four conditions:
- How fast BGP detects that a neighbor has become unreachable
- How many routing changes BGP needs to iterate over before a new stable state is reached
- The time between iterations
- If backup paths are immediately available or need one or more iterations to become available
Immediate availability of backup paths
Let’s look at the fourth condition first.
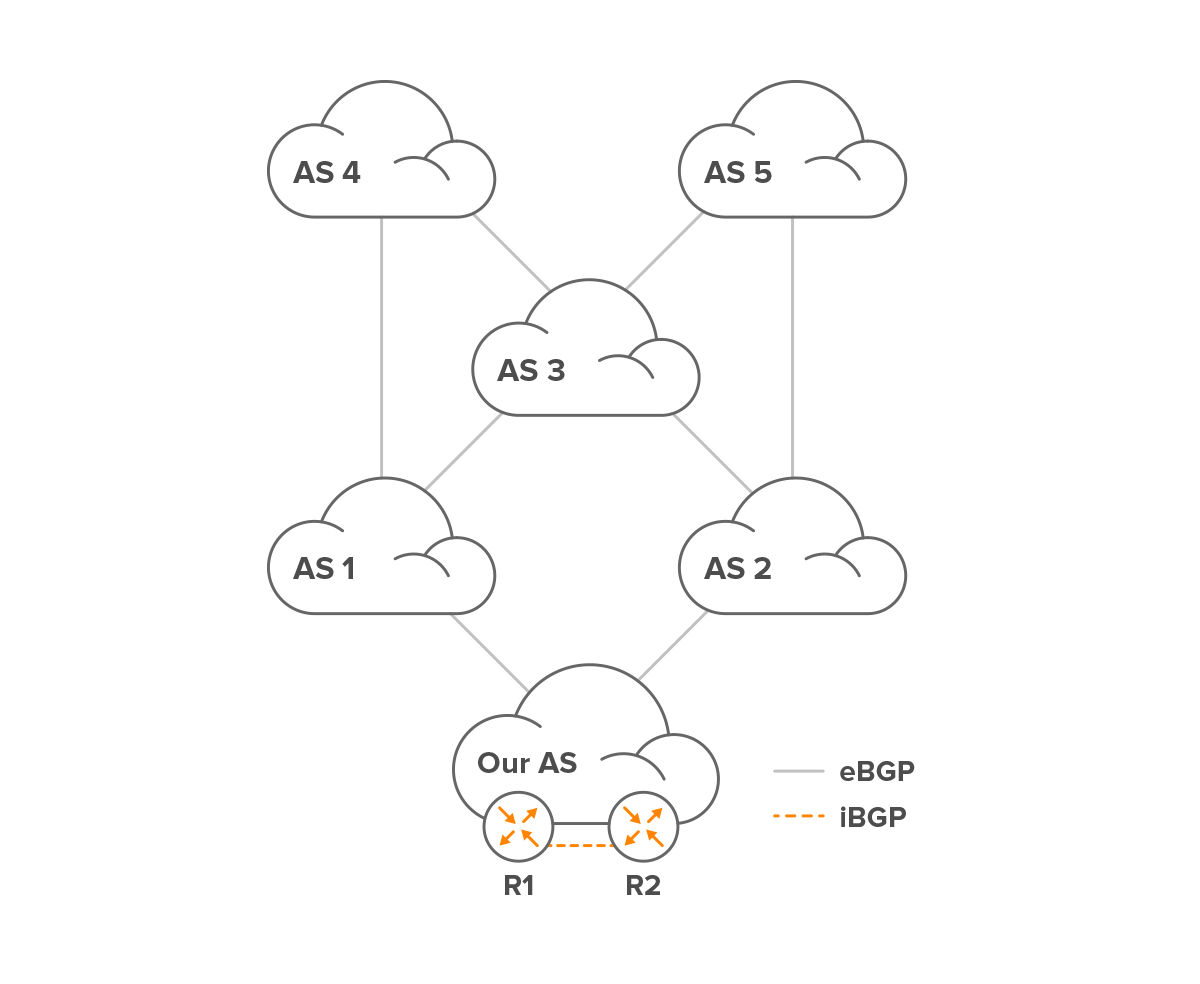
R1:
4: > 1 4 (eBGP)
2 3 4 (iBGP through R2)
5: 1 3 5 (eBGP)
> 2 5 (iBGP through R2)
R2:
4: > 1 4 (iBGP through R1)
2 3 4 (eBGP)
5: 1 3 5 (iBGP through R1)
> 2 5 (eBGP)
(The > character indicates the preferred path.)
Because R2 prefers to use the shorter path through R1 rather than its own longer eBGP path, it has to withdraw its announcement of the 2 3 4 path to R1. This is necessary to avoid the situation where R2 wants to use the path over R1, but R1 wants to use the path over R2, creating a routing loop. This means that the R1 BGP table ends up looking like this:
4: > 1 4 (eBGP) 5: 1 3 5 (eBGP) > 2 5 (iBGP through R2)
However, if R1 now loses its eBGP connection to AS 1, it needs to remove all paths learned from 1 from its BGP table, so that table becomes as follows:
5: > 2 5 (iBGP through R2)
This means that R1 no longer has a path toward destination 4, and any ongoing communication with AS 4 through R1 will start to lose packets and thus get stuck.
R1 has also told R2 to remove the paths through AS 1, so the R2 BGP table now looks like this:
4: > 2 3 4 (eBGP) 5: > 2 5 (eBGP)
At this point, R2’s best path to AS 4 is no longer through R1, so R2 is free to advertise the 2 3 4 path to R1 again. Which results in the following BGP table for R1:
4: > 2 3 4 (iBGP through R2) 5: > 2 5 (iBGP through R2)
At this point, R1 has a working path to AS 4 again, so new packets to AS 4 will no longer be lost, and if all of this has happened quickly enough, ongoing communication sessions will become “unstuck” and continue.
However, it is possible that the router returned “ICMP network unreachable” messages during the time that AS 4 was unreachable, and although this is not supposed to happen, the client or server communicating with AS 4 may have torn down its communication session because of those ICMP messages.
Adjusting the weight to keep backup paths visible
We can reduce or even negate the impact of BGP convergence by having R2 prefer its own longer path over 2 3 4 rather than R1’s shorter path. This way, R2 will keep announcing its longer path to R1, so if R1 loses its eBGP session to AS 1, it can immediately switch over to the 2 3 4 path through R2 that’s already in its BGP table.
Normally we’d increase the local preference to make a router prefer certain paths. However, the local preference is also communicated over iBGP, so R1 will also prefer the longer path, which is not what we want. A good solution, in this case, is for each router to set the “weight” parameter to a value higher than the default weight of 0 on prefixes learned over eBGP.
Weight is a Cisco proprietary attribute evaluated before the local preference, with a higher weight being more preferred. (Although invented by Cisco and not part of the BGP specification, many other vendors also implement it.) Unlike the local preference, the weight is not communicated over iBGP, so iBGP-learned paths will not have the higher weight. This is how to configure a higher weight for prefixes learned from a neighbor:
! router bgp 65000 neighbor 192.0.2.21 remote-as 65030 neighbor 192.0.2.21 route-map setweight in ! route-map setweight permit 10 set weight 5 !
Iterating faster
The issue we see here with iBGP, where several iterations of BGP updates are necessary, and during some of them, a router doesn’t have a path to a destination at all, can also happen with eBGP, although with the dense interconnectivity between internet service providers, this is less likely. It’s hard to reduce the number of iterations that BGP routers in other ASes need to converge, but it is possible to make the iterations happen faster. This is done by lowering the minimum route advertisement interval (MRAI).
The MRAI is how long a BGP router waits between sending updates for the same prefix. The idea is that if a number of updates for the same prefix arrive quickly after each other, it’s better to wait a bit and then act on the last one rather than bothering our BGP neighbors with each of those updates. The default MRAI value is 30 seconds for eBGP sessions and 5 seconds for iBGP sessions.
As the MRAI set on the other side of an eBGP session governs how fast we receive successive updates, it can be helpful to ask service providers to lower the MRAI on their BGP sessions to us, especially in situations where unreachability during BGP convergence by that ISP occurs. This is done as follows:
! router bgp 65000 neighbor 192.0.2.21 remote-as 65030 neighbor 192.0.2.21 advertisement-interval 5 !
Detecting broken BGP sessions faster
In most cases, the most important contributor to the temporary unreachability of parts of the internet during BGP convergence is waiting for BGP to realize there is a problem in the first place. To make sure neighboring BGP routers are reachable, BGP routers send periodic keepalive messages. If a router doesn’t see any incoming keepalive messages (or other BGP messages) for some time, it declares the neighbor dead and tears down the BGP session to that neighbor. Then the convergence process to find a new stable state to reach the affected prefixes starts.
The trouble with this system is that the hold time that counts down until a neighbor is declared dead is no less than 180 seconds (3 minutes!) by default on Cisco routers and some other BGP routers. It’s a good idea to set the hold time a good amount lower:
! router bgp 65000 timers bgp 6 20 neighbor 192.0.2.154 remote-as 65040 neighbor 192.0.2.154 timers 30 90 !
In this example, the default keepalive time and hold time for all BGP sessions are set to 6 and 20 seconds, respectively. For neighbor 192.0.2.154, the keepalive and hold times are set to 30 and 90 seconds.
In the BGP open message, both BGP speakers announce the hold time they’d like to use. The lower of the two will be used by both sides. The keepalive time is then set to a third of the negotiated hold time. The hold time must be at least 3 seconds. However, that’s quite aggressive if the BGP process on a router is running slowly, for instance, because a higher priority process needs most of the (often relatively modest) CPU capacity of the router. In that case, the BGP session may be declared dead, and unnecessary convergence cycles will be triggered.
An easy way to get around delays because of (relatively) long hold times is the “fast external fallover” feature that’s enabled by default on most routers. What this does is monitor the link state of the interface BGP is running over. If that interface goes down, the BGP session is also immediately brought down. As Ethernet (over fiber or UTP) constantly sends a signal that allows the other side to see the link is up, this works very well.
The big limitation is that a router can only detect a link going down if that link is connected to a router port. If there’s a switch in the middle, the switch will see the link going down, but the BGP process on the router won’t know about it. So ideally, connect long-distance links directly to router ports rather than having a switch in the middle. An alternative to this is using BFD.
BFD: bidirectional forwarding detection
Bidirectional forwarding detection (BFD) is a protocol for quick detection of link failures. It can be used with different routing protocols, including BGP. BFD is designed to, when possible, test whether the neighbor is still forwarding packets, not whether a routing protocol such as BGP is still running.
With BFD, it’s possible to detect failures within a few tens of milliseconds. However, this will easily detect failures that aren’t really there, so such aggressive timing should only be used if important applications really need it. BFD needs to be enabled on the interface(s) BGP runs over as well as on the BGP sessions themselves:
! interface GigabitEthernet0/0 bfd interval 300 min_rx 300 multiplier 3 ! router bgp 65000 neighbor 192.0.2.21 remote-as 65030 neighbor 192.0.2.21 fall-over bfd !
BFD has two main timers: one that indicates how fast we’re prepared to receive, and one that indicates how fast we want to send. These times are in milliseconds. During the BFD session establishment, this information is exchanged by both sides, so each will limit how often it sends test packets to stay within the receive interval of the other side. So both sides can send test packets at different rates. The multiplier is how many packets in a row must be lost before BFD declares the neighbor down. The default is 3.
So with 300 milliseconds for the transmit and receive timers, and assuming the neighbor accepts these, a failure will be detected between 600 and 900 milliseconds, allowing BGP convergence to start in less than a second.
BFD can also be used with internal routing protocols such as OSPF. OSPF normally needs 30 to 40 seconds to detect an outage, so BFD can improve that considerably.
Graceful restart
On modern routers, the routing protocols and other “control plane” activities run as software on a CPU, but the actual packet forwarding is typically done by special-purpose hardware (the “forwarding plane”). This makes it possible for routing protocols to go down while the packet forwarding continues. The normal BGP behavior to reroute affected destinations over alternative paths first and then try to re-establish the broken BGP session is suboptimal in this case, as the packets are still flowing.
Graceful restart (not to be confused with graceful shutdown) addresses this by keeping the packets flowing while a new BGP session is established.
Where BFD helps to switch to alternative paths as fast as possible when there is a failure, graceful restart does the opposite: it tries to hold on to existing paths as long as possible. So in situations where there are alternative paths and switching to them is easy, BFD shines. In situations where there are no alternative paths, graceful restart fits the bill.
Things get interesting when you use BFD and graceful restart together. The rationale would be that BFD was created to detect forwarding plane failures. If the BFD implementation can indeed detect that the forwarding plane of a neighbor still works even though the control plane has problems, then BFD has no reason to bring down a BGP session.
For instance, when the BGP implementation has crashed, but the BGP prefixes are still in the FIB (“forwarding information base”, the routing table used to forward packets). When BGP is restarted, it will reconnect, and a graceful restart makes sure there is no unnecessary FIB remove/reinstall cycle for BGP prefixes.
However, most BFD implementations aren’t quite capable of pulling this off. In those cases, BFD and graceful restart try to do opposite things, so it’s usually best not to actively use both at the same time.
Some “high availability” routers use graceful restart to be able to failover from one route processor (that handles the control plane) to another without interrupting packet forwarding. As such, it’s good to have graceful restart enabled in helper mode to facilitate the high availability functionality on other routers. This is often the default behavior for BGP implementations that support graceful restart. Actively using graceful restart requires activating it for one or more address families (i.e., IPv4 and/or IPv6).