

 Our previous article discusses flow-based SSH compromise detection. A force attack against SSH hosts consists of scan, brute-force and compromise phases that can be detected based on their typical traffic characteristics. For instance, during the SSH brute-force phase, Packets per Flow (PPF), Bytes per Flow (BPF) and duration values are alike. The series of login attempts is repeated in a loop, causing identical application-layer actions until the right login credentials are found. Traffic is flat in terms of PPF, BPF, and duration within the phase, changing only with the next phase. Therefore, a transition between phases can be reliably identified, making the attack easily detected based on NetFlow data.
Our previous article discusses flow-based SSH compromise detection. A force attack against SSH hosts consists of scan, brute-force and compromise phases that can be detected based on their typical traffic characteristics. For instance, during the SSH brute-force phase, Packets per Flow (PPF), Bytes per Flow (BPF) and duration values are alike. The series of login attempts is repeated in a loop, causing identical application-layer actions until the right login credentials are found. Traffic is flat in terms of PPF, BPF, and duration within the phase, changing only with the next phase. Therefore, a transition between phases can be reliably identified, making the attack easily detected based on NetFlow data.Force attacks against web applications are also very popular. Content Management Systems (CMS) such as WordPress, Drupal or Joomla enable people without any coding or programming knowledge to build working websites. According to statistics, WordPress is used by 33.2% of all the websites, that is a content management system market share of 60.1% [1]. A large market share, as well as the creators with a limited or non-technical knowledge relying on weak administrator passwords, make CMS the main target of force attacks, with WordPress being the most favorite.
Similar to an SSH attack, a force attack against a Content Management System consists of three phases. The scan phase includes scanning target URLs as multiple web sites can be hosted on a single web server in case of shared hosting. The goal is to find all virtual hosts associated with an IP address of a web server. In contrast to SSH, HTTP(s) is not a login-restrictive protocol that would make the detection of a brute-force against a web application much harder. An attacker can avoid detection based on NetFlow technology, creating additional network traffic between the brute force attempts. This might be done by page load or redirect as successful authentication is not required for these actions. In this case, PPF and BPF counters increase so the detection signatures may not be matched. Despite these limitations, Rick Hofstede and his colleagues from the University of Twente define HTTP(s) attacks signatures for the most common CMSs based on the used brute-force tools [2].
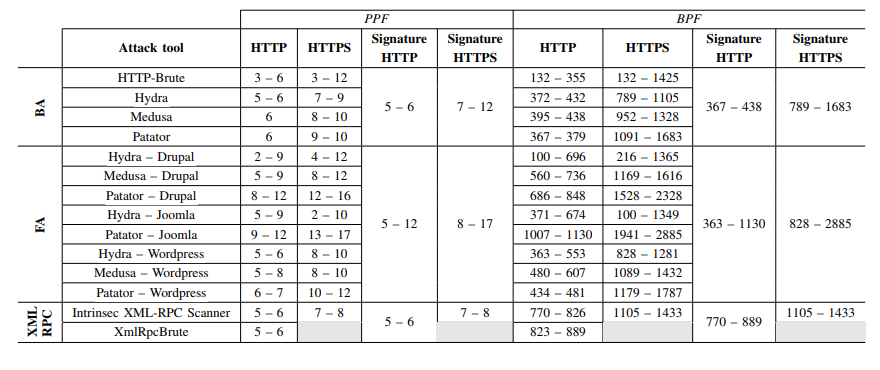
Table 1: Signatures for Detection of Brute-Force Phase of Attack Against Common CMSs
(Source: https://ris.utwente.nl/ws/portalfiles/portal/5492018/133801_2.pdf)
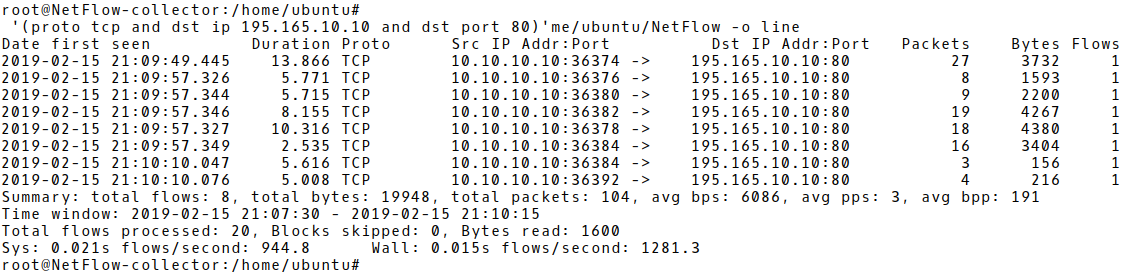
Based on the proposed PPF and BPF counters for WordPress and THC Hydra attack tool, we are going to simulate a brute-force attack and check if the suggested signature values are matched. Picture 1 depicts three flows, aggregating network data from one failed login attempt with Hydra, against URL http://195.165.10.10/wp-login.php – WordPress 5.0.2 (Picture 1). The first flow with PPF 7 and BPF 456 matches signature for HTTP based brute-force attack with Hydra.

Picture 1: Flow Records of a Single Failed Login Attempt with Hydra
The entire packet count for all three flows is 18. It correspondences with the Wireshark capture, filtered for the source address 10.10.10.10 (the attacker’s IP) and depicted in Picture 2. Notice the payload of the packet number 21. It contains a combination of a wrong username user and password 1111 sent within HTTP POST message to the victim (195.10.10.10).

Picture 2: Network Traffic of Brute-Force Attack Against WordPress with Hydra
Flow records generated after successful login to CMS WordPress via web interface are shown in Picture 3. Obviously, a combination of PPF and BPF values does not match the signatures listed in Table 1. The number of BPF values is significantly higher than it is in a case of failed login attempts.
Picture 3: Flow Records of Successful Login Attempt to WordPress
For the comparison between web server logs and detection results based on flow records, Hofstede summarizes detection accuracy in Table 2. He considers multiple values of the flow record threshold (N) of 6,9,14 and 37 flows, based on the distribution of attack sizes in terms of similar consecutive flow records. Detection accuracy increases with higher flow record thresholds and when both PPF and BPF values are taken into account. The False Positive Rate (FPR) decreases with higher threshold values. As Hofstede suggests, it is mainly caused by automated legitimate traffic, such as Web crawlers and calendar fetchers. This network traffic is similar to brute-force traffic, generating many small flows in terms of PPF and BPF. This, however, can have a great impact on Web site owners, as they often rely on search engine rankings for their income. Therefore, legitimate traffic catching represents a major disadvantage of a signature-based approach.
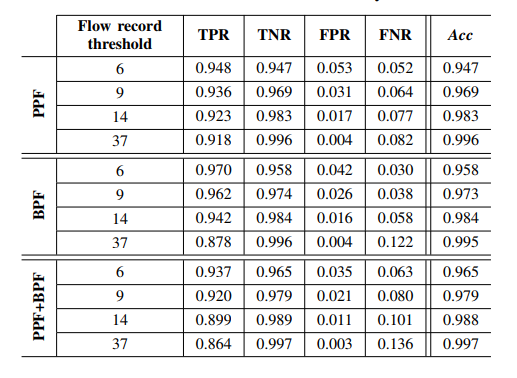
Table 2: Detection Accuracy of the Signature-based Brute-Force Attacks
(Source: https://ris.utwente.nl/ws/portalfiles/portal/5492018/133801_2.pdf)
To overcome the disadvantages of a signature-based approach, Hofstede introduces the advanced detection method of brute-force attacks against web applications. He defines the concept of histograms that can provide more details about packets in a flow. Histograms do not only reflect the total size of a specific flow, as is the case of regular NetFlow but the entire payload size distribution instead. For this reason, Hofstede defines an enterprise-specific IE for IPFIX so the payload histograms extend the size of flow by at most 37 bytes. Similar histograms are clustered so the histograms with similar packets, bytes, and duration are part of the same cluster. Hierarchical Cluster Analysis (HCA) is then used to build clusters based on inter-cluster distances in a hierarchical fashion. And what is the most important, histograms for benign connections are quite different from histograms in the typical brute-force attacks. According to Hosfstede, an advanced method reduces the number of false detection to almost 10% of existing works.
Conclusion:
Based on the work of Richard Hofstede, we have discussed the elementary (signature-based) detection approach of brute-force attack against web applications. Although this method brings satisfactory results, there are still false positives due to the existence of web crawlers and calendar fetchers that have similar traffic characteristics as brute-force attacks. In order to eliminate the disadvantages of the first method, Hofstede introduces the advanced method that is based on clustering histograms. This method eliminates false positives, reducing their count to 10%, however, it requires the definition of enterprise-specific information elements for IPFIX. The size of flow data also increases slightly (up to 37 Bytes per flow) due to the use of histograms that carry information about IP payload. Therefore, the amount of the exported information from exporter to a collector increases, as well.


